

How Do Web Crawlers Work? Complete Technical Guide
Learn how web crawlers work, from seed URLs to indexing. Understand the technical process, crawler types, robots.txt rules, and how crawlers impact SEO and affi...
9 min read

Get your
33% off
+ free AI Agent
Crawlers, also known as spiders or bots, systematically browse and index the internet, enabling search engines to understand and rank web pages for relevant queries.
Crawlers, also known as spiders or bots, are sophisticated automated software programs designed to systematically browse and index the vast expanse of the Internet. Their primary function is to help search engines understand, categorize, and rank web pages based on their relevance and content. This process is vital for search engines to deliver accurate search results to users. By continuously scanning web pages, crawlers build a comprehensive index that search engines like Google utilize to deliver precise and relevant search results.
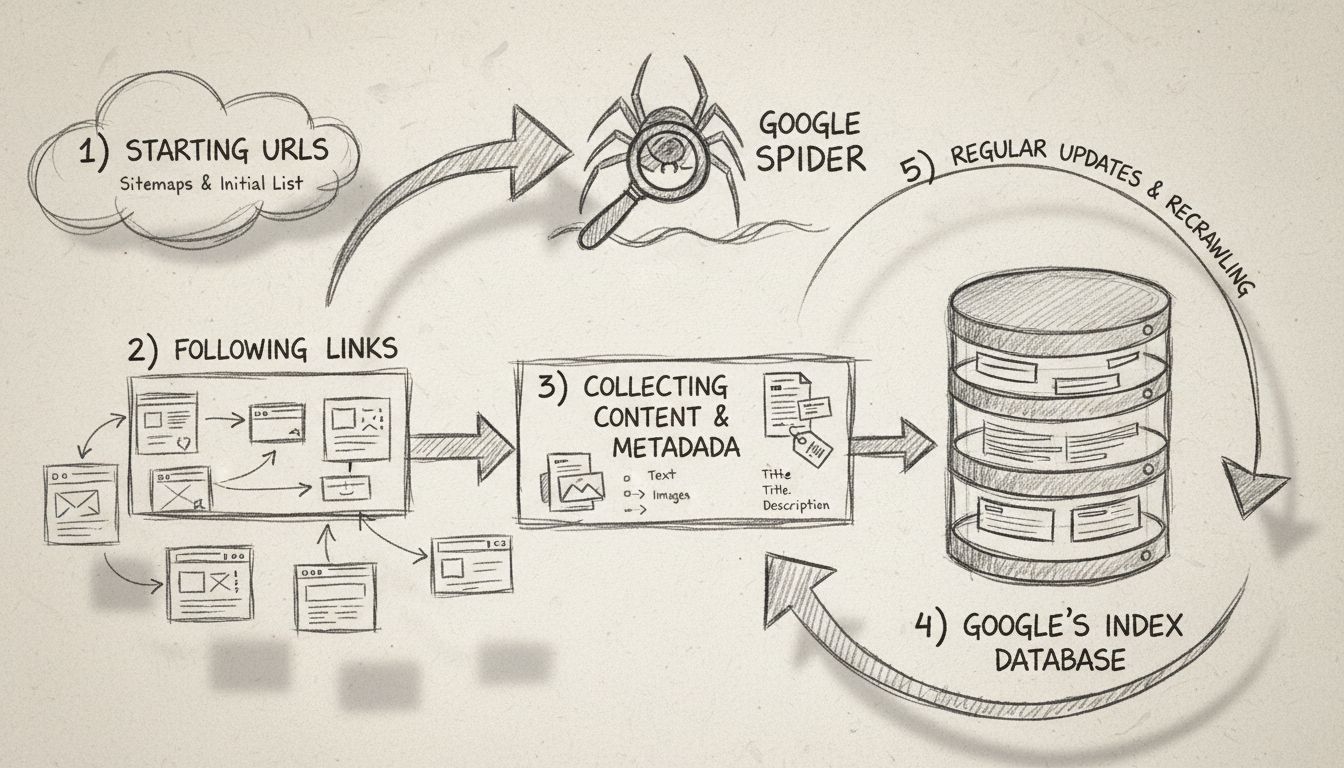
Web crawlers are essentially the eyes and ears of search engines, enabling them to see what is on each web page, understand its content, and decide where it fits in the index. They start with a list of known URLs and methodically work through each page, analyzing the content, identifying links, and adding them to their queue for future crawling. This iterative process allows crawlers to map the structure of the entire web, much like a digital librarian categorizing books.
Set up advanced tracking in minutes. No credit card required.
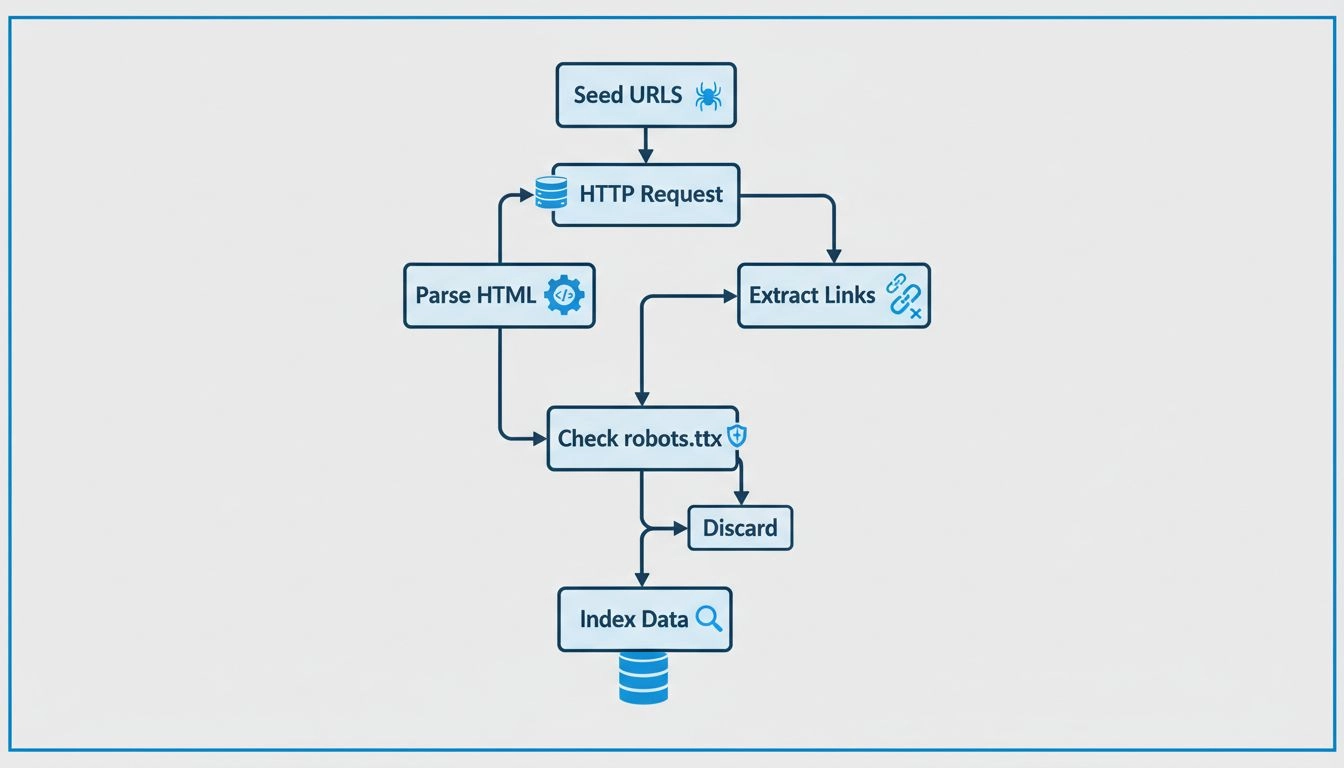
Crawlers operate by starting with a seed list of URLs, which they visit and inspect. As they parse these web pages, they identify links to other pages, adding them to their queue for subsequent crawling. This process enables them to map the web’s structure, following links from one page to another, akin to a digital librarian categorizing books. Each page’s content, including text, images, and meta tags, is analyzed and stored in a massive index. This index serves as the foundation for search engines to retrieve relevant information in response to user queries.
Web crawlers work by consulting the robots.txt file of each webpage they visit. This file provides rules that indicate which pages should be crawled and which should be ignored. After checking these rules, crawlers proceed to navigate the webpage, following hyperlinks according to predefined policies, such as the number of links pointing to a page or the page’s authority. These policies help prioritize which pages are crawled first, ensuring that more important or relevant pages are indexed promptly.
As they crawl, these bots store the content and metadata of each page. This information is crucial for search engines in determining the relevance of a page to a user’s search query. The collected data is then indexed, allowing the search engine to quickly retrieve and rank pages when a user performs a search.
For affiliate marketers , understanding the functionality of crawlers is essential for optimizing their websites and improving search engine rankings. Effective SEO involves structuring web content in a way that is easily accessible and understandable to these bots. Important SEO practices include:
Be the first to know about new features and product updates.
In the context of affiliate marketing , crawlers have a nuanced role. Here are some key considerations:
Affiliate marketers can utilize tools like Google Search Console to gain insights into how crawlers interact with their sites. These tools provide data on crawl errors, sitemap submissions, and other metrics, enabling marketers to enhance their site’s crawlability and indexing. Monitoring crawl activity helps identify issues that may hinder indexing, allowing for timely corrections.
Indexed content is essential for visibility in search engine results. Without being indexed, a web page won’t appear in search results, regardless of its relevance to a query. For affiliates , ensuring that their content is indexed is crucial for driving organic traffic and conversion rates. Proper indexing ensures that content can be discovered and ranked appropriately.
Technical SEO involves optimizing the website’s infrastructure to facilitate efficient crawling and indexing. This includes:
Structured Data: Implementing structured data helps crawlers understand the content’s context, improving the site’s chances of appearing in rich search results. Structured data provides additional information that can enhance search visibility.
Site Speed and Performance: Fast-loading sites are favored by crawlers and contribute to a positive user experience. Enhanced site speed can lead to better rankings and increased traffic.
Error-Free Pages: Identifying and rectifying crawl errors ensures that all important pages are accessible and indexable. Regular audits help maintain site health and improve SEO performance.

Learn how understanding and optimizing for crawlers can boost your website’s visibility and search engine ranking.
Learn how web crawlers work, from seed URLs to indexing. Understand the technical process, crawler types, robots.txt rules, and how crawlers impact SEO and affi...
Spiders are bots created for spamming, which may cause your business a lot of problems. Learn more about them in the article.
Learn what Google Spider (Googlebot) is, how it crawls and indexes websites, and why it's essential for SEO. Discover how to optimize your site for better crawl...
Join our community of happy clients and provide excellent customer support with Post Affiliate Pro.
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.