Discover why statistical significance matters in data analysis, research, and business decisions. Learn about p-values, hypothesis testing, and how to interpret results correctly.
Why is statistical significance important?
Statistical significance is important because it measures how likely it is that a result occurred by chance. It helps researchers and businesses distinguish between genuine effects and random variation, enabling confident decision-making based on reliable evidence rather than coincidence.
Understanding Statistical Significance in Modern Data Analysis
Statistical significance serves as the foundation for evidence-based decision-making across industries ranging from pharmaceutical research to digital marketing and affiliate program management. At its core, statistical significance answers a fundamental question: Is the observed result a genuine effect or merely a product of random chance? This distinction is critical because organizations invest substantial resources based on data insights, and acting on false conclusions can lead to wasted budgets, ineffective strategies, and missed opportunities. By establishing rigorous statistical standards, professionals can confidently implement changes knowing their decisions rest on solid evidence rather than coincidence.
The importance of statistical significance extends beyond academic research into practical business applications. When an affiliate marketer tests a new promotional strategy, when a pharmaceutical company evaluates a new drug’s effectiveness, or when an e-commerce platform optimizes its checkout process, statistical significance provides the objective framework needed to validate findings. Without this framework, organizations would struggle to distinguish between temporary fluctuations and meaningful trends, potentially making costly decisions based on noise in the data.
The Foundation: P-Values and Hypothesis Testing
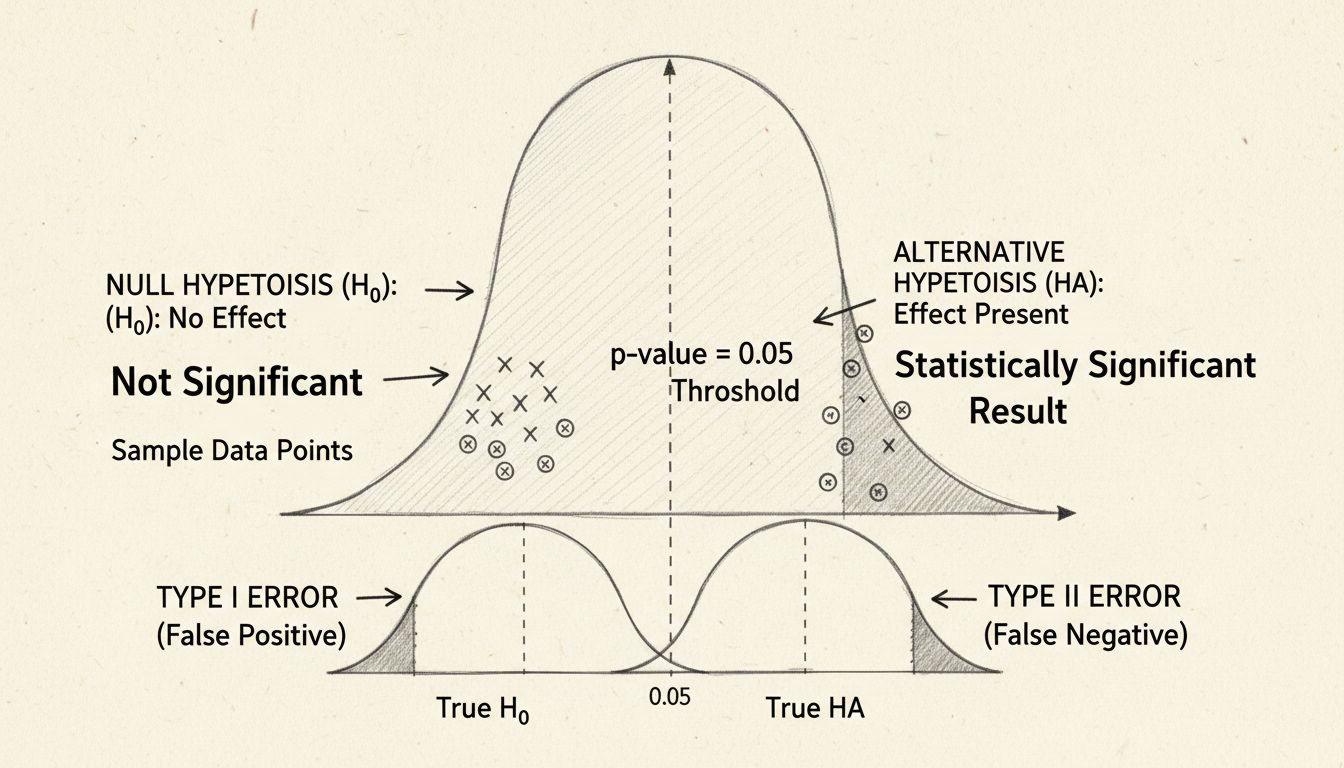
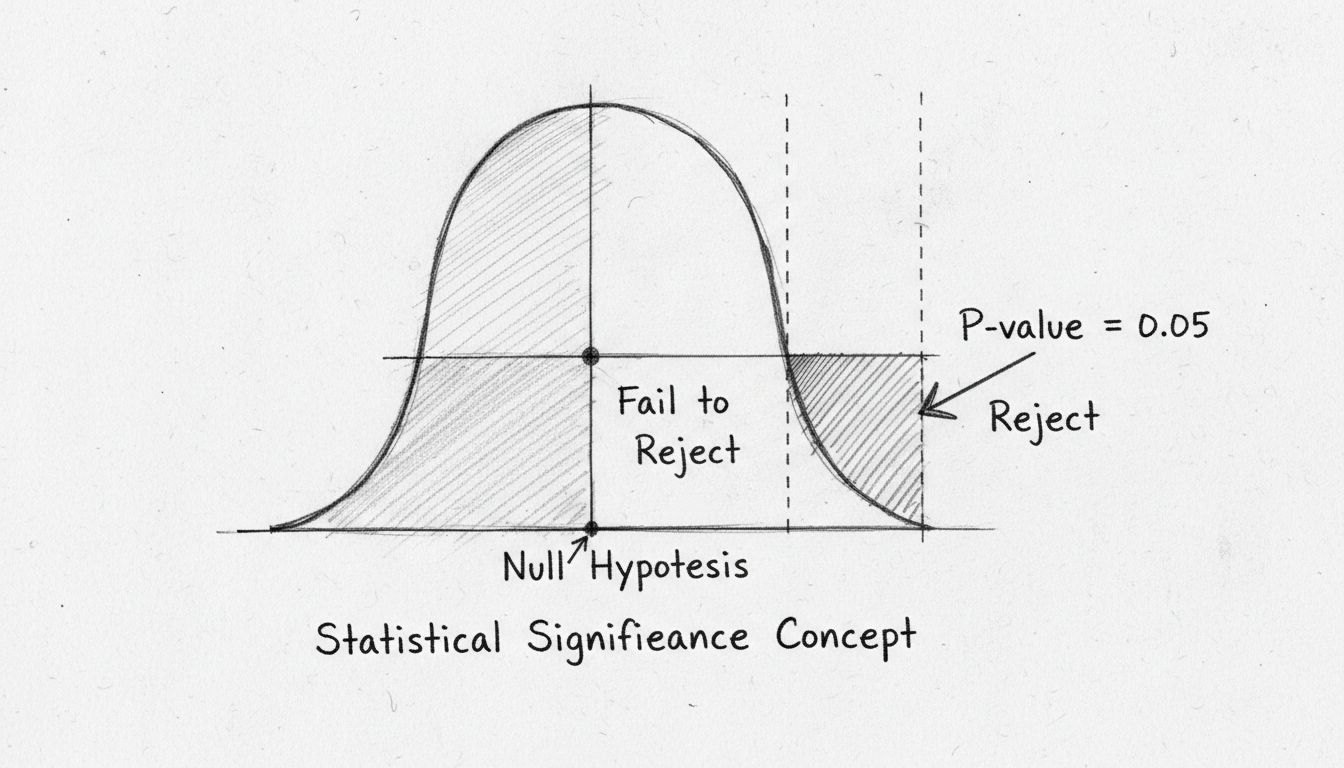
The p-value represents the probability of observing results as extreme as those measured, assuming the null hypothesis (the assumption that there is no real effect) is true. This metric has become the standard tool for assessing statistical significance across scientific and business domains. A p-value of 0.05 or lower is conventionally considered statistically significant, meaning there is less than a 5% probability that the observed result occurred purely by chance. This threshold, established by statistician Ronald Fisher in the 1920s, has become the industry standard because it balances the need for confidence with practical feasibility.
Understanding p-values requires recognizing what they do and do not represent. A common misconception is that a p-value indicates the probability that the null hypothesis is true—this is incorrect. Instead, the p-value tells you how likely your observed data would be if the null hypothesis were actually true. A small p-value suggests strong evidence against the null hypothesis, supporting the alternative hypothesis that a real effect exists. Conversely, a large p-value indicates insufficient evidence to reject the null hypothesis, though this does not prove the null hypothesis is true; it simply means the data do not provide compelling evidence against it.
Launch your affiliate program today
Set up advanced tracking in minutes. No credit card required.
One of the most critical functions of statistical significance is its ability to separate genuine patterns from random noise in data. In any dataset, some variation is inevitable due to sampling error, measurement imprecision, and natural randomness. Without statistical significance testing, organizations cannot reliably determine whether observed differences represent true effects or merely reflect this inherent variability. For example, if an affiliate program sees a 2% increase in conversion rates after implementing a new tracking system, statistical significance testing reveals whether this improvement is likely to persist or if it might disappear in the next reporting period due to random fluctuation.
This distinction becomes particularly important when making resource allocation decisions. Suppose a company tests two different email subject lines and observes that one generates 3% more clicks than the other. Statistical significance testing determines whether this 3% difference is likely to be reproducible or if it could easily occur by chance with different sample data. If the difference is statistically significant with a large sample size, the company can confidently adopt the better-performing subject line. If the difference is not statistically significant, the company should recognize that the observed difference might not reflect a true superiority and should either collect more data or treat both options as equivalent.
Minimizing Decision-Making Errors
Statistical significance helps organizations balance two types of errors that can occur in hypothesis testing: Type I errors (false positives) and Type II errors (false negatives). A Type I error occurs when researchers incorrectly conclude that an effect exists when it actually does not—essentially seeing a pattern that is not really there. A Type II error occurs when researchers fail to detect a real effect that does exist. The significance level (typically 0.05) directly controls the probability of committing a Type I error, limiting it to 5% when the null hypothesis is true.
Correctly identifying that a new affiliate commission structure truly improves recruiter performance
By establishing predetermined significance levels before conducting analysis, organizations create a structured framework that prevents both over-enthusiasm (acting on false positives) and excessive skepticism (missing real opportunities). This disciplined approach is particularly valuable in affiliate marketing, where decisions about commission structures, promotional strategies, and partner recruitment directly impact profitability.
Join our newsletter
Be the first to know about new features and product updates.
Supporting Informed Decision-Making Across Industries
Statistical significance provides the confidence necessary for organizations to make substantial investments based on research findings. In pharmaceutical development, regulatory agencies require statistical significance to approve new medications, ensuring that observed health benefits are genuine rather than coincidental. In digital marketing, statistical significance validates that A/B test results justify implementing new website designs, email campaigns, or advertising strategies. In affiliate program management, statistical significance confirms that changes to commission structures, tracking methods, or partner incentives actually improve performance metrics.
The standardized nature of statistical significance testing creates a common language across industries and organizations. When a researcher reports that findings are statistically significant at the p < 0.05 level, professionals worldwide understand this means the probability of the result occurring by chance is less than 5%. This standardization enables consistent decision-making frameworks and allows organizations to compare results across different studies, time periods, and contexts. PostAffiliatePro leverages these statistical principles in its analytics engine, enabling affiliate managers to identify genuinely high-performing partners and strategies rather than acting on temporary fluctuations.
The Critical Distinction Between Statistical and Practical Significance
An essential nuance in understanding statistical significance is recognizing that it differs from practical significance. A result can be statistically significant—meaning it is unlikely to have occurred by chance—while having minimal real-world impact. Conversely, a result might have substantial practical importance but fail to reach statistical significance due to small sample sizes or high data variability. This distinction becomes crucial when interpreting research findings and making business decisions.
For instance, imagine a study with 10,000 participants showing that a new affiliate recruitment strategy increases partner sign-ups by 0.5% with a p-value of 0.03 (statistically significant). While this result is statistically significant, the practical impact might be negligible if the cost of implementing the new strategy exceeds the revenue generated by the additional 0.5% of partners. Conversely, a study with only 50 participants might show a 15% improvement in affiliate retention but fail to reach statistical significance due to the small sample size. In this case, the practical importance might justify further investigation despite the lack of statistical significance.
Key Factors Affecting Statistical Significance
Several factors influence whether a result achieves statistical significance, and understanding these factors helps organizations design better studies and interpret results more accurately. Sample size represents one of the most important determinants—larger samples provide more reliable estimates and increase the ability to detect genuine effects. With a small sample, even substantial real effects might not reach statistical significance due to high variability. Conversely, with very large samples, even trivial effects might become statistically significant, highlighting why practical significance must also be considered.
Effect size measures the magnitude of the difference between groups or the strength of a relationship between variables. Large effect sizes are easier to detect and more likely to be statistically significant, while small effect sizes require larger samples to achieve significance. Variability in the data also matters significantly—datasets with high variability make it harder to detect effects because the noise obscures the signal. Techniques like standardization, blocking, or controlling for confounding variables can reduce variability and increase the likelihood of detecting genuine effects. Multiple comparisons present another consideration: when conducting many statistical tests simultaneously, the probability of observing at least one false positive increases substantially, requiring adjustments to the significance level to maintain overall accuracy.
Best Practices for Reporting and Interpreting Statistical Significance
When communicating statistical findings, clarity and transparency are paramount. Effective reporting includes the specific statistical test used, the p-value obtained, the significance level chosen, the sample size, and the effect size. This comprehensive information allows readers to evaluate the reliability and practical importance of findings. Additionally, researchers should discuss any limitations, potential confounding variables, and assumptions underlying the analysis. PostAffiliatePro’s reporting features exemplify this approach by providing detailed metrics alongside confidence intervals and effect sizes, enabling affiliate managers to make fully informed decisions.
A critical best practice is avoiding over-reliance on p-values as the sole measure of significance. Modern statistical practice increasingly emphasizes reporting confidence intervals, which provide a range of plausible values for the true effect rather than just a binary significant/not significant determination. Confidence intervals offer richer information about the precision of estimates and the practical magnitude of effects. For example, a 95% confidence interval for a conversion rate improvement might be 2% to 8%, indicating that while the effect is statistically significant, the true magnitude could vary considerably. This information helps decision-makers assess whether the potential benefit justifies implementation costs.
Avoiding Common Misconceptions and Pitfalls
Numerous misconceptions about statistical significance can lead to flawed interpretations and poor decisions. One widespread misunderstanding is the belief that a statistically significant result proves the alternative hypothesis is true. In reality, statistical significance only indicates that the observed data are unlikely under the null hypothesis; it does not prove causation or establish absolute truth. Another common error is assuming that a non-significant result means no effect exists. Non-significant results simply indicate insufficient evidence to reject the null hypothesis, which could result from small sample sizes, high variability, or genuinely absent effects.
The practice of “p-hacking”—exhaustively testing multiple hypotheses until finding statistically significant results—represents a serious pitfall that inflates false positive rates. When researchers conduct numerous tests without adjusting significance levels, they dramatically increase the probability of observing significant results by chance alone. This problem becomes particularly acute in exploratory data analysis where many potential relationships are tested. Responsible statistical practice requires either pre-specifying hypotheses before analysis or adjusting significance levels when conducting multiple comparisons using methods like Bonferroni correction.
Statistical Significance in the Context of Affiliate Marketing
For affiliate program managers, statistical significance provides essential guidance for optimizing performance and allocating resources effectively. When testing new commission structures, recruitment strategies, or tracking technologies, statistical significance determines whether observed performance changes represent genuine improvements or temporary fluctuations. PostAffiliatePro’s analytics platform incorporates statistical significance testing into its core functionality, enabling managers to confidently identify high-performing affiliates, validate the effectiveness of program changes, and make data-driven decisions about resource allocation.
Consider a scenario where an affiliate program manager implements a new tiered commission structure and observes that average affiliate earnings increase by 8% in the first month. Statistical significance testing reveals whether this improvement is likely to persist or if it might disappear as the program stabilizes. If the improvement is statistically significant across a representative sample of affiliates, the manager can confidently maintain the new structure. If it is not statistically significant, the manager should either collect more data or investigate whether other factors (seasonal trends, external market changes) might explain the apparent improvement. This disciplined approach prevents costly mistakes and ensures that program modifications genuinely enhance performance.
Statistical significance remains indispensable for modern data analysis and decision-making. By providing an objective framework for distinguishing genuine effects from random variation, statistical significance enables organizations to make confident, evidence-based decisions. Understanding its principles, limitations, and proper application is essential for anyone working with data, whether in research, business analytics, or affiliate program management. As data becomes increasingly central to organizational strategy, the ability to correctly interpret statistical significance becomes a critical competitive advantage.
Make Data-Driven Decisions with Confidence
PostAffiliatePro's advanced analytics and reporting tools help you track affiliate performance with statistical rigor. Understand which marketing strategies truly drive results and optimize your affiliate program based on reliable data insights.
How is Statistical Significance Used? Complete Guide for Data-Driven Decisions
Learn how statistical significance determines whether results are real or due to chance. Understand p-values, hypothesis testing, and practical applications for...
Statistical significance expresses the reliability of measured data, helping businesses distinguish real effects from chance and make informed decisions, especi...