
Crawlers and Their Role in Search Engine Ranking
Crawlers accumulate data and information from the internet by visiting websites and reading the pages. Find out more about them.
5 min read
SEO
Crawlers
+4

Learn why web crawlers are called spiders, how they work, and their critical role in search engine indexing. Discover the technical mechanisms behind web crawling in 2025.
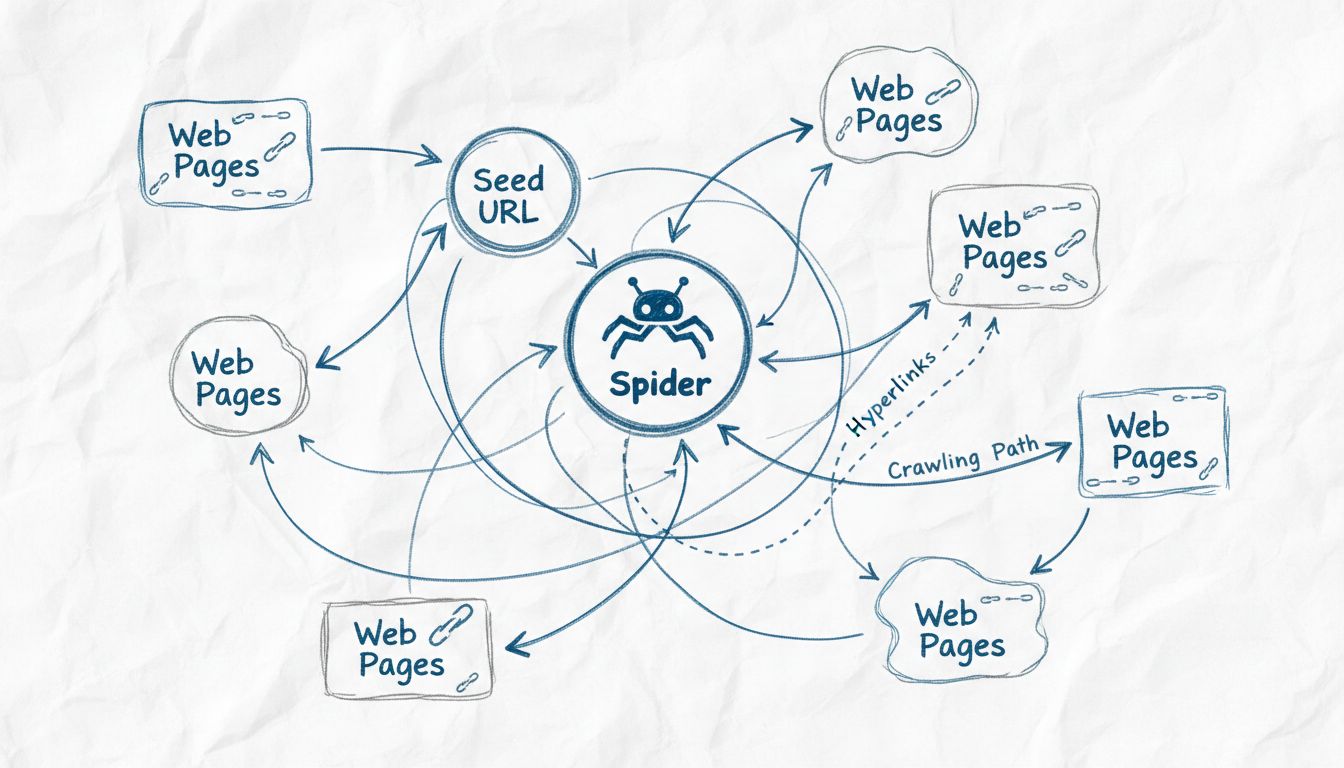
Web crawlers are called spiders because they systematically crawl through the web following links from one page to another, similar to how a spider navigates its web. The term 'spider' is a fitting metaphor for these automated bots that traverse the interconnected network of websites to discover, index, and organize web content for search engines.
The term “spider” for web crawlers originates from a clever metaphorical comparison between how these automated bots navigate the internet and how actual spiders navigate their webs. Just as a spider weaves an intricate web to catch and organize information about its environment, web crawlers traverse the interconnected network of hyperlinks across the World Wide Web to discover, analyze, and organize digital content. The metaphor is particularly apt because both entities operate systematically through complex networks, following pathways to reach new destinations and gather information. This naming convention has become so ingrained in technology that the terms “spider,” “crawler,” and “bot” are now used interchangeably when discussing web indexing technology. The visual and conceptual similarity between a spider’s web and the structure of the internet makes this terminology both intuitive and memorable for both technical professionals and general users.
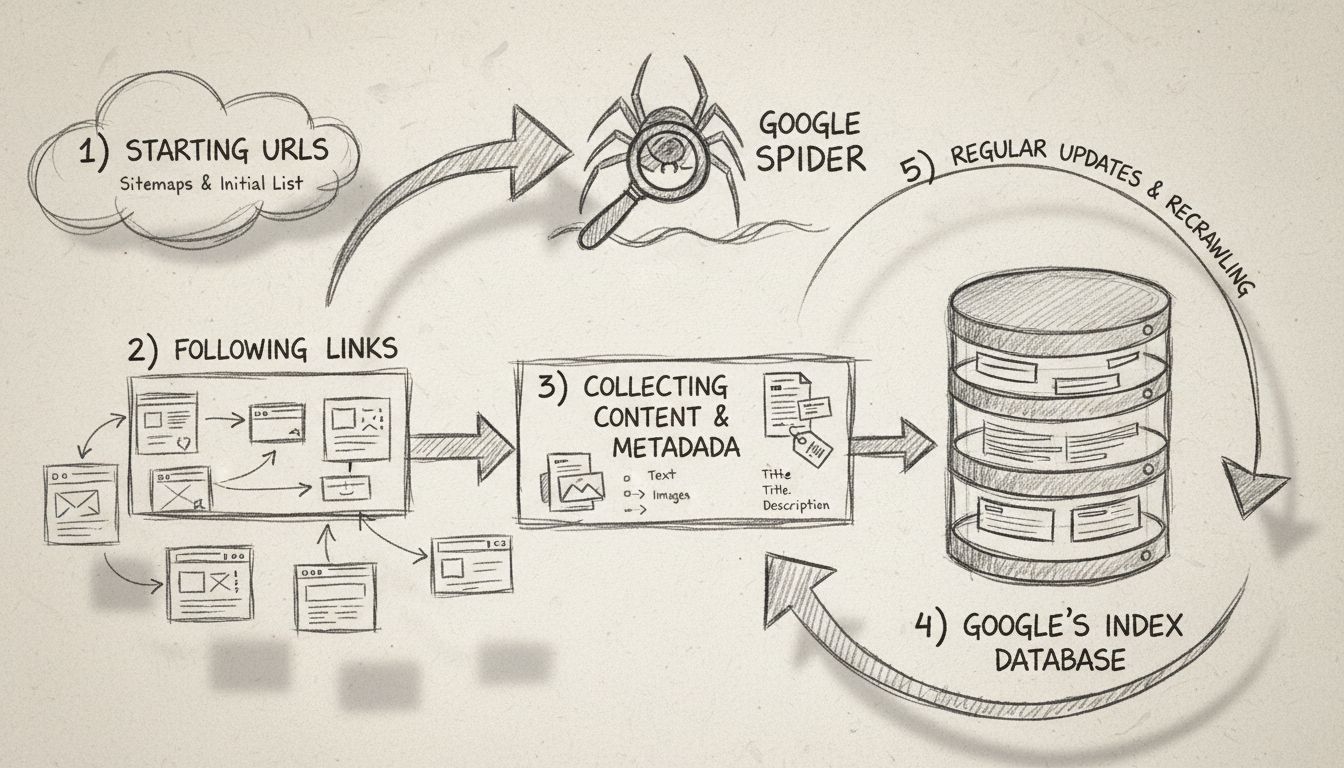
Web spiders operate through a sophisticated yet systematic process that begins with a single entry point known as a “seed URL.” From this starting location, the spider analyzes the HTML code of the webpage, extracting all hyperlinks present on that page. The spider then follows these links to new pages, repeating the process continuously to expand its reach across the web. This methodical approach allows spiders to discover millions of interconnected pages without requiring manual direction or human intervention. The spider maintains what is known as a “crawl frontier,” which is essentially a queue of URLs that have been discovered but not yet visited. Based on specific crawling policies and algorithms, the spider prioritizes which URLs to visit next, considering factors such as page importance, update frequency, and relevance to the search engine’s indexing goals.
| Crawler Component | Function | Purpose |
|---|---|---|
| URL Queue | Stores list of pages to visit | Organizes crawling sequence |
| Parser | Reads page content and HTML | Extracts links and metadata |
| Indexer | Stores page information | Creates searchable database |
| Scheduler | Determines crawl frequency | Manages resource allocation |
| User-Agent | Identifies the crawler | Communicates with servers |
Set up advanced tracking in minutes. No credit card required.
Modern web spiders are built on a sophisticated technical architecture that enables them to process vast amounts of data efficiently. The core components of a web crawler include the URL frontier management system, which organizes and prioritizes URLs for crawling; the fetching mechanism, which downloads page content at high speeds; the parsing engine, which extracts links and metadata from HTML; and the indexing system, which stores processed information for search retrieval. Web spiders must also implement politeness policies to avoid overwhelming target servers with excessive requests, revisit policies to determine how frequently pages should be re-crawled for updates, and selection policies to decide which links are most valuable to follow. Contemporary spiders have evolved to handle JavaScript and AJAX content, though they still prioritize standard HTML for reliable content discovery. The distributed nature of modern crawling means that large-scale spiders operate across multiple servers simultaneously, allowing them to crawl different websites in parallel and dramatically increase their overall efficiency and coverage.
While the terms “spider” and “crawler” are often used interchangeably, it’s important to understand that they represent the same technology with different naming conventions. However, web spiders differ significantly from web scrapers, which are sometimes confused with crawlers. The primary distinction lies in their purpose and scope: web crawlers focus on general information gathering about websites and their structure, following links broadly across the web to build comprehensive indexes. Web spiders, when used specifically by search engines, concentrate on indexing textual content to make it searchable and discoverable. Web scrapers, by contrast, are precision tools designed to extract specific data elements from websites, such as product prices, contact information, or reviews. Scrapers typically target particular websites or data types rather than crawling broadly across the web. Additionally, crawlers and spiders generally respect robots.txt files and website terms of service, while scrapers may operate without such constraints. Understanding these distinctions is crucial for website owners and developers who need to manage how their content is accessed and indexed by automated systems.
Be the first to know about new features and product updates.
Web spiders come in various forms, each designed for specific purposes and applications. Search engine spiders like Googlebot are the most well-known type, used by major search engines to discover and index web pages for search results. Focused crawlers, on the other hand, limit their scope to specific topics or areas of the internet, creating detailed indexes of niche content. Web analysis spiders help webmasters monitor their own websites by tracking metrics such as site visits, broken links, and page performance. Price comparison spiders automatically gather pricing information from multiple vendors, allowing comparison websites to provide users with current market data. Email validation spiders verify email addresses and check for deliverability issues. Each type of spider serves a distinct purpose in the digital ecosystem, and understanding these differences helps website owners optimize their sites for the appropriate crawlers.
Web spiders are absolutely fundamental to how search engines operate and provide value to users worldwide. Without spiders continuously crawling and indexing web content, search engines would have no way to know what websites exist, what content they contain, or how relevant that content might be to user queries. When a spider crawls a webpage, it evaluates numerous factors including page structure, content relevance, keyword usage, and user experience signals. This information is then stored in massive indexes that search engines use to match user queries with the most relevant results. The quality and frequency of spider crawling directly impacts how quickly new content appears in search results and how accurately search engines can rank pages. Search engines like Google, Bing, Baidu, and Yahoo each maintain their own proprietary spider bots—Googlebot, Bingbot, Baiduspider, and Slurp respectively—each with unique algorithms and crawling strategies optimized for their specific search engine’s goals and user base.
| Spider Bot | Search Engine | Primary Function | Crawl Strategy | Key Features |
|---|---|---|---|---|
| Googlebot | Index web pages for Google Search | Distributed crawling with mobile and desktop variants | Handles JavaScript, prioritizes mobile-first indexing, respects crawl budget | |
| Bingbot | Microsoft Bing | Index web pages for Bing Search | Parallel crawling across multiple servers | Efficient bandwidth usage, respects robots.txt, supports multiple content types |
| Baiduspider | Baidu | Index web pages for Baidu Search | Optimized for Chinese language content | Specialized for Asian web content, handles simplified and traditional Chinese |
| DuckDuckBot | DuckDuckGo | Index web pages for privacy-focused search | Respectful crawling with emphasis on privacy | Minimal data collection, respects user privacy preferences |
| YandexBot | Yandex | Index web pages for Yandex Search | Distributed crawling with regional optimization | Optimized for Russian and Eastern European content |
Website owners have several tools and strategies available to optimize how spiders crawl and index their content. Creating a comprehensive sitemap.xml file provides spiders with a clear roadmap of all pages that should be indexed, significantly improving crawl efficiency and ensuring no important pages are missed. Optimizing meta tags, including title tags and meta descriptions, helps spiders understand page content and improves how pages appear in search results. Implementing a well-structured robots.txt file allows website owners to guide spiders toward important content and away from pages that shouldn’t be indexed, such as admin panels or duplicate content. Regularly updating and adding fresh content encourages spiders to revisit websites more frequently, keeping indexes current and improving search visibility. Website owners should also ensure their site architecture is clean and logical, with clear hierarchical navigation that makes it easy for spiders to discover all pages. Improving page load speed is critical because spiders have limited crawl budgets—the amount of resources search engines allocate to crawling a specific site—and faster pages allow spiders to crawl more content within that budget.
Despite their sophistication, web spiders face numerous technical challenges that can limit their effectiveness. Dynamic content generated by JavaScript presents a significant hurdle, as not all spiders can execute JavaScript code to render pages as users see them. Rate limiting imposed by websites restricts how many requests spiders can make within a given timeframe, potentially preventing complete indexing of large websites. CAPTCHA challenges and other anti-bot measures can block spider access to content, though legitimate search engine spiders are typically whitelisted. Duplicate content across multiple URLs confuses spiders about which version should be indexed and ranked, potentially diluting search visibility. Crawler traps—intentional or accidental infinite loops in website structure—can waste spider resources and consume crawl budgets without productive indexing. Additionally, the exponential growth of web content means spiders cannot possibly crawl and index everything, requiring sophisticated algorithms to prioritize which content is most important to index. Password-protected pages and authenticated content remain largely inaccessible to public spiders, limiting indexing of private or membership-based content.
Web spider technology continues to evolve rapidly as the internet grows and becomes more complex. Modern spiders are increasingly capable of handling advanced web technologies including single-page applications, progressive web apps, and dynamic content rendering. Artificial intelligence and machine learning are being integrated into spider algorithms to better understand content context, user intent, and page quality. The rise of generative AI has created new demands for web crawling, as AI systems require constantly updated, relevant, and accurate information to function effectively. Enterprise web crawlers have become increasingly sophisticated, allowing businesses to crawl their own websites for internal search functionality, content management, and performance monitoring. The focus on crawl efficiency has intensified as websites grow larger and more complex, with spiders now implementing smarter prioritization algorithms to maximize the value of each crawl request. Privacy considerations are also shaping spider development, with increased emphasis on respecting user privacy while still enabling effective content discovery and indexing. Looking forward, web spiders will likely become even more intelligent and efficient, leveraging advanced technologies to navigate an increasingly complex digital landscape while respecting website policies and user privacy.
Just as web spiders systematically crawl and index the entire web, PostAffiliatePro systematically tracks and optimizes every affiliate relationship in your network. Our advanced tracking technology ensures no commission goes unrecorded and no opportunity is missed.
Crawlers accumulate data and information from the internet by visiting websites and reading the pages. Find out more about them.
Spiders are bots created for spamming, which may cause your business a lot of problems. Learn more about them in the article.
Learn what Google Spider (Googlebot) is, how it crawls and indexes websites, and why it's essential for SEO. Discover how to optimize your site for better crawl...
Join our community of happy clients and provide excellent customer support with Post Affiliate Pro.
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.