What is a Spider Computer Virus? Definition, Threats & Protection Guide
Learn what spider computer viruses are, how they spread across networks, and discover effective protection strategies. Comprehensive guide to understanding self-replicating malware threats in 2025.
What is a spider computer virus?
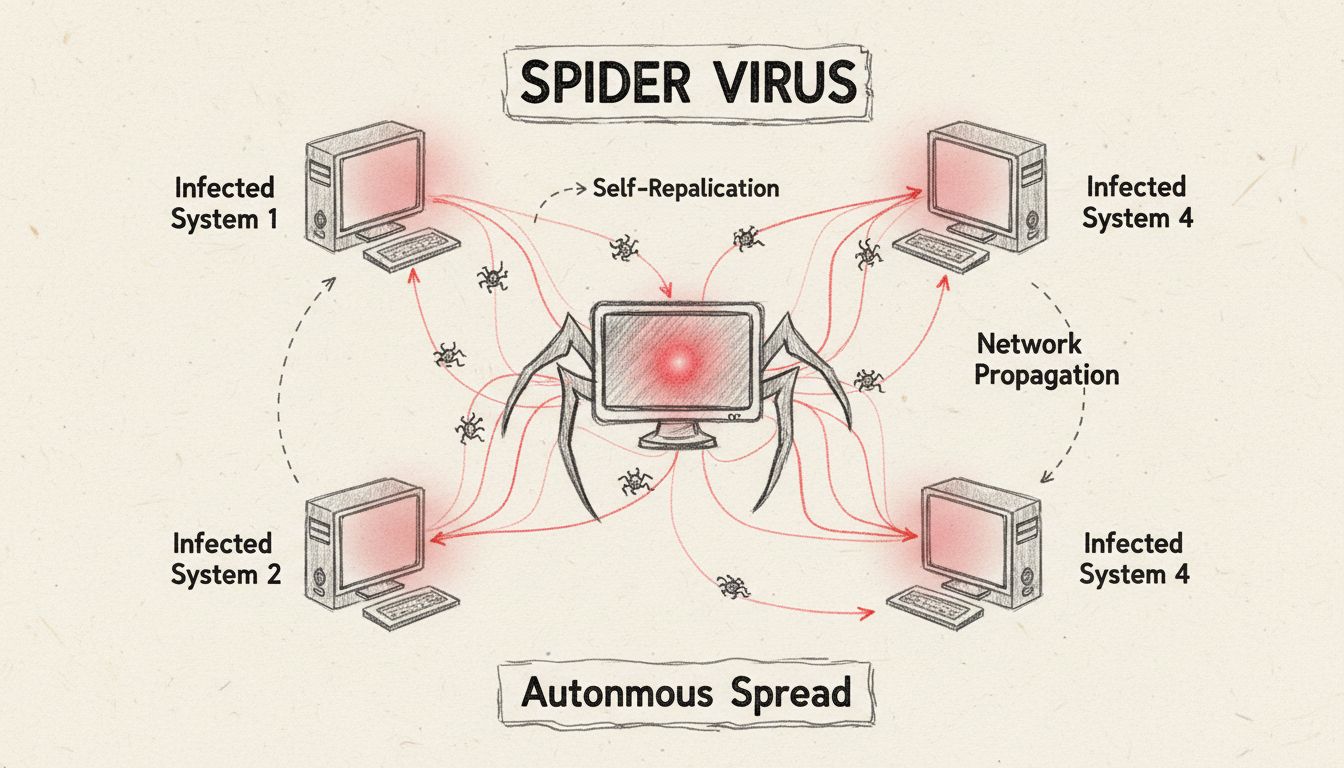
A spider computer virus is a self-replicating malware designed to spread itself by infecting other computers across networks. Unlike traditional viruses, spider viruses operate autonomously, propagating through network connections without requiring user intervention, making them particularly dangerous for organizations.
Understanding Spider Computer Viruses
A spider computer virus represents a sophisticated category of self-replicating malware that operates with remarkable autonomy across interconnected computer networks. The term “spider” metaphorically describes how these viruses spread their infection like a spider weaving its web across multiple systems, creating an expanding network of compromised devices. Unlike traditional computer viruses that require user action to propagate, spider viruses exploit network vulnerabilities to replicate and spread independently, making them exponentially more dangerous in enterprise environments. The fundamental characteristic that distinguishes spider viruses from conventional malware is their ability to function as standalone programs that can identify, infiltrate, and compromise other systems without human intervention or activation of host files.
How Spider Viruses Differ from Traditional Viruses
The distinction between spider viruses and traditional computer viruses is critical for understanding modern cybersecurity threats. Traditional viruses require a host file to attach themselves to, and they only activate when a user executes that infected file or program. In contrast, spider viruses operate as independent entities that can replicate and spread across networks immediately upon system infiltration. This fundamental difference means that spider viruses can compromise an entire network infrastructure within hours, whereas traditional viruses typically affect individual computers or require user interaction to spread. The propagation mechanism of spider viruses leverages network connections, email systems, file-sharing protocols, and system vulnerabilities to create exponential growth in infections across connected devices.
Characteristic
Spider Virus
Traditional Virus
Host Requirement
Operates independently
Requires host file
Activation Method
Automatic upon entry
Requires user action
Spread Mechanism
Network-based autonomous replication
File-based manual transfer
Speed of Propagation
Exponential (hours to days)
Linear (days to weeks)
User Intervention Needed
No
Yes
Network Impact
Entire infrastructure at risk
Individual systems primarily affected
Detection Difficulty
High (operates in background)
Moderate (visible file changes)
Launch your affiliate program today
Set up advanced tracking in minutes. No credit card required.
Spider viruses employ sophisticated propagation techniques that exploit multiple vectors simultaneously to maximize infection rates across networks. Once a spider virus gains entry to a system, it immediately begins scanning the network for vulnerable targets, identifying computers with outdated software, unpatched security vulnerabilities, or weak authentication mechanisms. The virus then replicates itself and transmits copies to these vulnerable systems through various channels including email protocols, network file-sharing services, instant messaging platforms, and direct network connections. This autonomous replication process creates a cascading effect where each newly infected computer becomes a distribution point for further infections, exponentially increasing the number of compromised systems within the network infrastructure.
The initial infection vector for spider viruses typically involves phishing emails with malicious attachments, compromised websites hosting malware downloads, or exploitation of known security vulnerabilities in unpatched systems. Once executed on a target system, the spider virus establishes persistence mechanisms that allow it to survive system reboots and evade antivirus detection. Many modern spider viruses carry additional payloads such as ransomware, spyware, or backdoor trojans that enable attackers to maintain long-term access to compromised systems. The virus may also install itself into the system’s boot sector or create hidden processes that consume system resources while remaining invisible to standard security monitoring tools.
Real-World Examples of Spider-Like Malware
Several notorious malware families demonstrate spider virus characteristics through their autonomous propagation capabilities. The Morris Worm, released in 1988, became one of the first documented examples of a self-replicating network worm that spread across thousands of computers, causing an estimated $10-100 million in damages. The Storm Worm of 2007 infected over 1.2 billion email systems and created a botnet of approximately one million compromised computers that remained active for over a decade. The SQL Slammer worm generated random IP addresses and attempted to infect them indiscriminately, resulting in over 75,000 infected computers participating in coordinated DDoS attacks within hours of its release. More recently, the WannaCry ransomware incorporated worm-like propagation mechanisms that allowed it to spread across networks exploiting the EternalBlue vulnerability, affecting hundreds of thousands of systems globally within days.
File Spider ransomware represents a contemporary example of spider-like malware that combines autonomous propagation with encryption capabilities. This ransomware spreads through malicious email attachments containing MS Office documents with macro commands that download and execute the malware payload. Upon infiltration, File Spider encrypts files with AES-128 encryption and appends the “.spider” extension to encrypted files, rendering them inaccessible. The malware employs RSA encryption for key management, storing decryption keys on remote servers controlled by cybercriminals. These examples illustrate how spider viruses have evolved from simple self-replicating programs into sophisticated multi-stage attacks that combine autonomous propagation with destructive payloads designed to maximize damage and financial gain.
Join our newsletter
Be the first to know about new features and product updates.
Identifying Spider Virus Infections
Detecting spider virus infections requires vigilance and understanding of common indicators that suggest network compromise. Organizations should monitor for unusual network traffic patterns, particularly unexpected outbound connections to unfamiliar IP addresses or domains that may indicate command-and-control communications. System performance degradation including unexplained CPU usage spikes, excessive disk I/O operations, and network bandwidth consumption often signal active malware propagation. Email systems may exhibit suspicious activity such as mass emails being sent from user accounts without authorization, or unusual email forwarding rules being created automatically. Security event logs frequently show failed login attempts, privilege escalation activities, or creation of new user accounts that attackers use to maintain persistent access to compromised systems.
Additional indicators include unexpected system crashes, blue screen errors, or spontaneous reboots that may occur as the virus attempts to exploit system vulnerabilities or evade detection mechanisms. Users may notice unfamiliar programs launching at startup, strange desktop icons appearing, or browser settings being modified without authorization. File system anomalies such as unexpected file modifications, creation of hidden directories, or changes to system files can indicate active malware presence. Network administrators should implement continuous monitoring of network traffic patterns, file integrity monitoring systems, and behavioral analysis tools that can detect anomalous activities characteristic of spider virus propagation before widespread network compromise occurs.
Protection Strategies Against Spider Viruses
Comprehensive protection against spider viruses requires a multi-layered security approach that addresses multiple attack vectors simultaneously. Organizations must maintain current security patches for all operating systems and applications, as spider viruses frequently exploit known vulnerabilities that have available patches. Implementing robust firewall solutions with intrusion detection and prevention capabilities can block unauthorized network connections and identify suspicious traffic patterns indicative of malware propagation. Advanced endpoint protection solutions utilizing behavioral analysis, machine learning algorithms, and sandboxing technologies can detect and isolate spider viruses before they establish persistence on systems.
Network segmentation represents a critical defensive strategy that limits the lateral movement of spider viruses across infrastructure by isolating critical systems and sensitive data from general-purpose networks. Organizations should implement strict access controls, enforce strong authentication mechanisms including multi-factor authentication, and maintain detailed audit logs of all system access and modifications. Regular security awareness training for employees reduces the likelihood of successful phishing attacks that serve as initial infection vectors for spider viruses. Maintaining offline backups of critical data ensures that organizations can recover from ransomware attacks without paying extortion demands to cybercriminals. Implementing email security solutions that scan attachments, block suspicious links, and authenticate sender identities can prevent malicious emails from reaching end users. PostAffiliatePro provides comprehensive security features integrated into its affiliate marketing platform to protect partner networks from malware threats and ensure secure transaction processing across all connected systems.
Removal and Recovery from Spider Virus Infections
Responding effectively to spider virus infections requires immediate action to contain the threat and minimize damage to organizational systems and data. Upon detection of a spider virus infection, organizations should immediately isolate affected systems from the network to prevent further propagation to uncompromised computers. Disconnecting infected systems from both wired and wireless network connections stops the virus from spreading to other devices while allowing security teams to analyze and remediate the infection. External storage devices should be disconnected from infected systems to prevent the virus from spreading to backup systems or portable media that could reinfect the network later.
Professional incident response teams should conduct comprehensive forensic analysis of infected systems to identify the infection vector, determine the scope of compromise, and recover evidence for potential law enforcement involvement. Antivirus and anti-malware tools should be deployed to scan systems in safe mode with networking disabled, which minimizes the number of active processes and provides a cleaner environment for malware detection and removal. System restoration from clean backups created before the infection occurred represents the most reliable recovery method, as it ensures complete removal of all malware components and restoration of system integrity. Organizations should implement enhanced monitoring and detection systems following recovery to identify any remaining malware or backdoors that attackers may have installed for persistent access. Regular security assessments and penetration testing help identify vulnerabilities that spider viruses could exploit, enabling organizations to strengthen defenses before attacks occur.
Protect Your Affiliate Network from Malware Threats
PostAffiliatePro provides comprehensive security features to protect your affiliate marketing platform from malware infections and cyber threats. Secure your network infrastructure and ensure safe transactions for all partners.
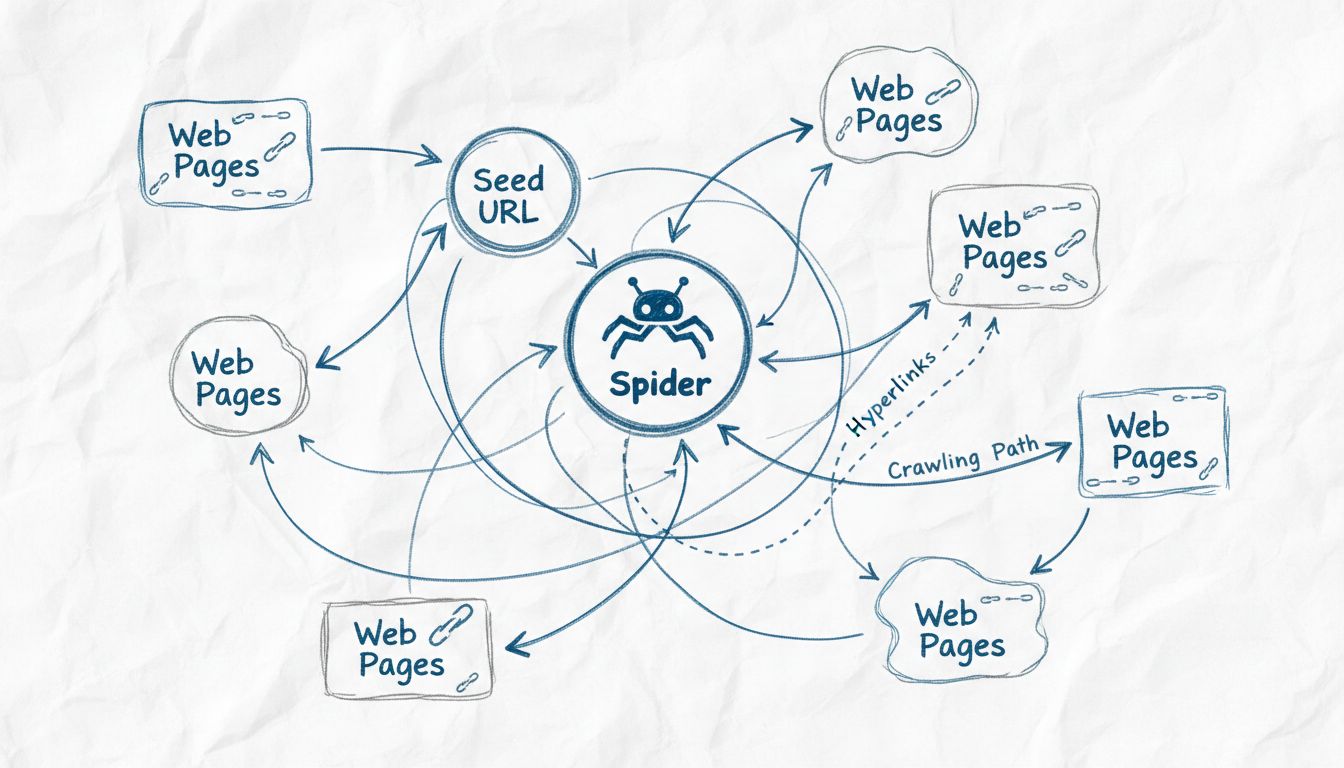
Why Are Web Crawlers Called Spiders? Understanding Web Indexing Technology
Learn why web crawlers are called spiders, how they work, and their critical role in search engine indexing. Discover the technical mechanisms behind web crawli...