
Indexing (Indexed)
Indexing is a process when a certain webpage is found by crawlers. Key signals are noticed and all data is tracked in the index.
4 min read
Indexing
SEO
+3
Learn what page indexing means, why pages aren’t indexed by Google, and how to fix indexing issues. Discover technical solutions and best practices for 2025.
When a page is not indexed, it means the search engine has not added it to its database, so it will not appear in search results. This can happen due to technical issues like noindex tags or robots.txt blocks, crawl errors, duplicate content, poor quality, or simply because the page hasn't been discovered yet.
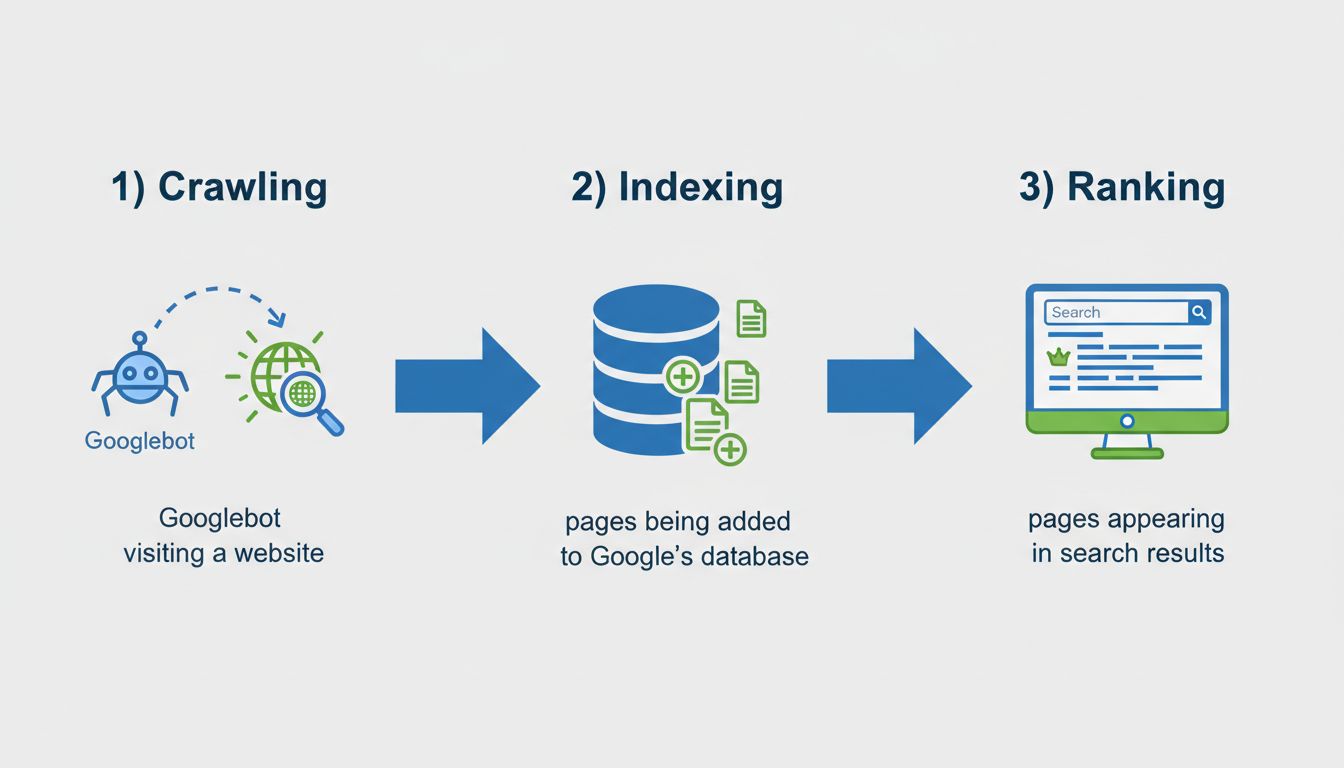
When a page is “not indexed,” it means that Google’s search engine has not added it to its database, making it invisible to search results. This is fundamentally different from a page that exists but simply doesn’t rank well for specific keywords. Understanding the distinction between indexing and ranking is crucial for anyone managing online content or running affiliate marketing campaigns. Indexing is the prerequisite step that must occur before a page can even have a chance to rank in search results. Without indexing, your content is essentially invisible to search engines and potential visitors who rely on Google to discover information. The indexing process involves three critical stages: crawling (when Googlebot visits your page), indexing (when the page is added to Google’s database), and ranking (when the page appears in search results for relevant queries).
There are numerous reasons why a page might not be indexed, and they generally fall into three main categories: technical issues, content quality problems, and discovery issues. Understanding each category helps you diagnose and fix indexing problems more effectively. The most common technical barriers include noindex meta tags, robots.txt restrictions, canonical tag conflicts, and server errors. Content-related issues typically involve thin or duplicate content, poor quality, or content that doesn’t match user search intent. Discovery problems occur when Google simply hasn’t found your page yet due to lack of internal links, missing sitemap entries, or the page being too new.
Noindex Meta Tags and Robots.txt Blocks
One of the most frequent culprits behind non-indexed pages is the presence of a noindex meta tag. This HTML directive explicitly tells search engines not to index a page, even if they can crawl it successfully. The tag appears in the page’s source code as <meta name="robots" content="noindex">. Sometimes these tags are added accidentally during development or by SEO plugins configured incorrectly. To check if your page has a noindex tag, right-click on the page, select “View Page Source,” and search for “noindex.” You can also use Google Search Console’s URL Inspection Tool, which will clearly indicate if a page is blocked by a noindex tag.
The robots.txt file is another critical technical barrier. This file controls which parts of your website Googlebot is allowed to crawl. If your important pages are blocked in robots.txt with a “Disallow” directive, Google won’t be able to crawl them, and consequently won’t index them. You can check your robots.txt file by visiting yourdomain.com/robots.txt in your browser. Look for lines starting with “Disallow” and verify that important sections like /blog/ or /products/ aren’t accidentally blocked.
Canonical Tag Misconfigurations
Canonical tags tell Google which version of a page should be indexed when duplicates exist. If a canonical tag points to the wrong URL—such as your homepage or a completely different page—Google may ignore the page you want indexed. Each page should ideally have a self-referencing canonical tag pointing to itself. You can check this by viewing the page source and searching for link rel="canonical". If the URL in the canonical tag doesn’t match your current page URL, that’s your problem.
Server Errors and HTTP Status Codes
When Googlebot tries to crawl a page and encounters server errors (5xx status codes) or page not found errors (404 status codes), it interprets this as a signal that the page isn’t available or functional. If these errors persist over time, Google may remove the page from its index entirely. You can check your site’s crawl errors in Google Search Console under the “Coverage” report, which shows pages with problematic HTTP status codes.
Thin and Low-Quality Content
Google increasingly prioritizes content quality and relevance. Pages with thin content—meaning they lack sufficient depth, detail, or value—are often excluded from the index. This includes pages with very few words, generic information, or content that doesn’t adequately answer user queries. Google’s algorithms assess whether content provides genuine value to searchers. If a page contains outdated information, lacks original insights, or simply repeats information available elsewhere, Google may determine it’s not worth indexing.
Duplicate Content Problems
When multiple pages on your site contain identical or near-identical content, Google typically indexes only one version and marks the others as duplicates. This is common with product descriptions copied from manufacturers, blog posts with minimal variations, or service pages repeated across different locations. Duplicate content also wastes your crawl budget, as Googlebot must spend resources identifying that pages are duplicates rather than crawling new, unique content.
Search Intent Mismatch
Pages that don’t align with user search intent are frequently excluded from indexing. For example, if you create a page about “SEO tools” but the page is actually a blog post rather than a tool comparison (which is what most searchers expect), Google may determine the page isn’t relevant for that query and won’t index it. Understanding search intent by analyzing top-ranking results before creating content is essential.
Orphaned Pages and Internal Linking
Pages without internal links pointing to them are called “orphaned pages.” If a page isn’t linked from anywhere on your site and isn’t in your sitemap, Google may never discover it. Even if Google does find it, the lack of internal links signals that the page isn’t important, which can result in it not being indexed. Internal links serve as pathways for Googlebot to discover content and also pass authority and relevance signals.
Missing Sitemap Entries
A sitemap is a file that lists your website’s important pages, helping Google discover and prioritize them for crawling. If a page isn’t included in your sitemap, it’s harder for Google to find it, especially if it also lacks internal links. While pages can still be indexed without being in a sitemap, inclusion significantly improves discoverability.
Crawl Budget Limitations
Larger websites have a limited “crawl budget”—the number of pages Google will crawl within a given timeframe. If your site has many low-quality pages, slow loading times, or excessive duplicate content, Google may allocate fewer resources to crawling your site. This means some pages may not be crawled and indexed promptly, or at all.
Set up advanced tracking in minutes. No credit card required.
Google Search Console is the primary tool for diagnosing why pages aren’t indexed. The platform provides detailed reports showing exactly which pages are indexed and why others aren’t. To access this information, navigate to your Search Console property, click on “Indexing” in the left menu, then select “Pages.” This report shows your indexed pages and provides a breakdown of non-indexed pages by reason.
| Issue Type | Status in GSC | What It Means | Solution |
|---|---|---|---|
| Noindex Tag | Excluded by ’noindex’ tag | Page has noindex directive | Remove noindex tag from page |
| Robots.txt Block | Blocked by robots.txt | Page disallowed in robots.txt | Update robots.txt to allow crawling |
| Duplicate Content | Duplicate without user-selected canonical | Multiple similar pages exist | Add canonical tags or consolidate content |
| Low Quality | Discovered – currently not indexed | Page deemed low value | Improve content depth and quality |
| Not Discovered | Discovered – currently not indexed | Page not yet crawled | Add internal links and submit sitemap |
| Server Error | Crawl anomaly | Server returned error | Fix server issues and resubmit |
The URL Inspection Tool is another powerful feature. Simply paste a specific URL into the search bar at the top of Search Console, and Google will show you whether that page is indexed, when it was last crawled, and any issues preventing indexing. If a page isn’t indexed, the tool will explain why and often provide a “Request Indexing” button to ask Google to recrawl the page.
Removing Technical Barriers
Start by addressing technical issues. If your page has a noindex tag and you want it indexed, remove the tag from the page’s HTML. In WordPress, this is typically done through your SEO plugin (Yoast, Rank Math, All in One SEO) by unchecking the “Allow search engines to index this page” option. If the page is blocked in robots.txt, update your robots.txt file to allow crawling of that section. For canonical tag issues, ensure each page has a self-referencing canonical tag pointing to itself.
Improving Content Quality
If your page is marked as “Discovered – currently not indexed” or “Crawled – currently not indexed,” the issue is likely content quality. Expand your content to provide more comprehensive information, add original insights or data, ensure it matches search intent, and remove any duplicate content. Make sure your page actually answers the questions users are asking when they search for related terms.
Enhancing Internal Linking
Add internal links from relevant pages on your site to the non-indexed page. These links should use descriptive anchor text and be placed naturally within content. Aim for 2-5 internal links per page. Additionally, ensure the page is included in your XML sitemap and that the sitemap is submitted to Google Search Console.
Submitting for Indexing
After making fixes, use the URL Inspection Tool in Google Search Console to request indexing. Google will recrawl the page and reassess whether it should be indexed. While there’s no guaranteed timeline, pages are typically recrawled within a few days to a couple of weeks.
Be the first to know about new features and product updates.
Maintaining good indexing health requires ongoing attention. Regularly audit your site using Google Search Console to monitor indexing status. Ensure your robots.txt file is correctly configured and doesn’t accidentally block important content. Implement proper canonical tags across your site, especially if you have multiple versions of similar content. Maintain consistent internal linking practices, linking related content together to help Google understand your site structure. Finally, focus on creating high-quality, original content that provides genuine value to your audience. This is the most effective long-term strategy for ensuring your pages get indexed and ranked.
Track and manage your affiliate campaigns effectively with PostAffiliatePro's advanced tracking and analytics. Ensure your content reaches the right audience and maximize your affiliate revenue with our industry-leading platform.
Indexing is a process when a certain webpage is found by crawlers. Key signals are noticed and all data is tracked in the index.
Learn 7 proven methods to check if your website is indexed by Google. Use Google Search Console, site operators, URL inspection tools, and more to verify indexi...
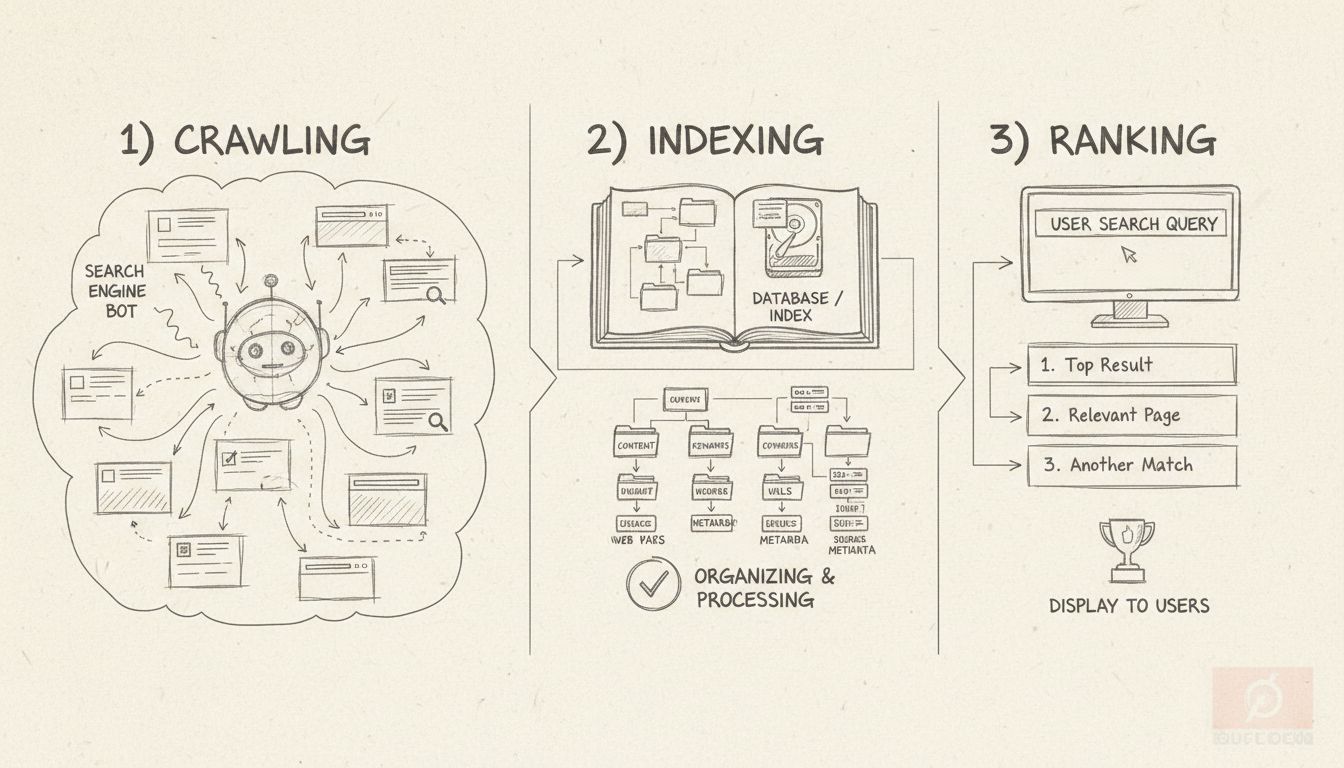
Learn what SEO indexing means, how it works, and why it's critical for your website's search visibility. Discover best practices to ensure your pages get indexe...
Join our community of happy clients and provide excellent customer support with Post Affiliate Pro.
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.