How to Fix Duplicate Content Issues: Complete SEO Guide
Learn proven methods to fix duplicate content issues including 301 redirects, canonical tags, and noindex directives. Protect your SEO rankings with PostAffiliatePro’s expert strategies.
How can I fix duplicate content issues?
Fix duplicate content issues using 301 redirects to consolidate pages, implementing rel="canonical" tags to specify preferred versions, using noindex directives for syndicated content, and maintaining consistent internal linking. These methods prevent search engines from splitting your ranking power across multiple URLs.
Understanding Duplicate Content and Its SEO Impact
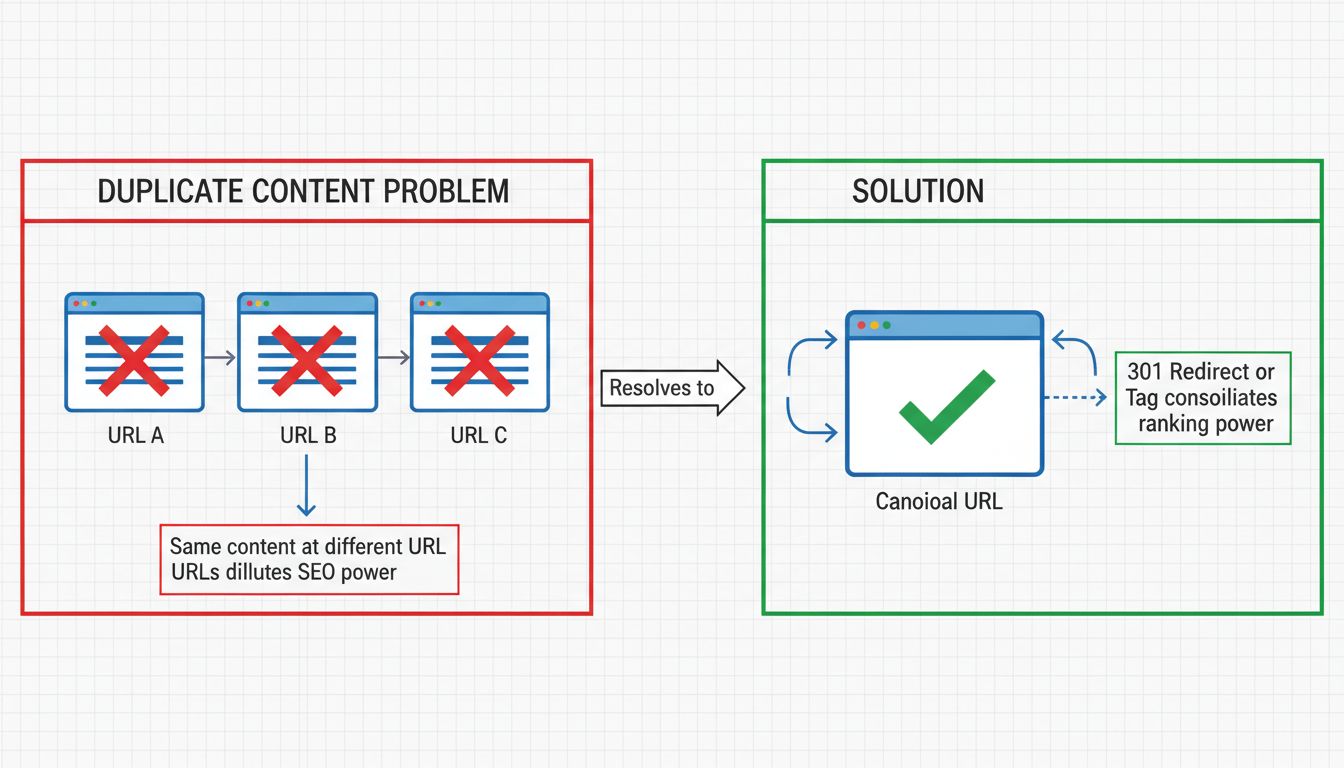
Duplicate content occurs when identical or highly similar content appears at multiple URLs on the internet. This issue can happen internally within your own website or externally when other websites republish your content without permission. According to recent data, approximately 29% of the web consists of duplicate content, making this one of the most prevalent technical SEO challenges website owners face today. When search engines encounter multiple versions of the same content, they struggle to determine which version is most relevant to user queries, leading to diluted ranking power and reduced visibility for all versions of the page.
The impact of duplicate content extends beyond simple ranking confusion. Search engines allocate a limited crawl budget to each website, which represents the number of pages they will crawl and index within a given timeframe. When search engines waste this valuable budget crawling multiple versions of identical content, they have less capacity to discover and index your new and updated pages. This creates a cascading effect where fresh, important content gets delayed in appearing in search results. Additionally, when multiple versions of your content exist across different URLs, any backlinks pointing to those pages get split among the duplicates, significantly diluting the link equity that would otherwise concentrate on a single authoritative version.
Common Causes of Duplicate Content Issues
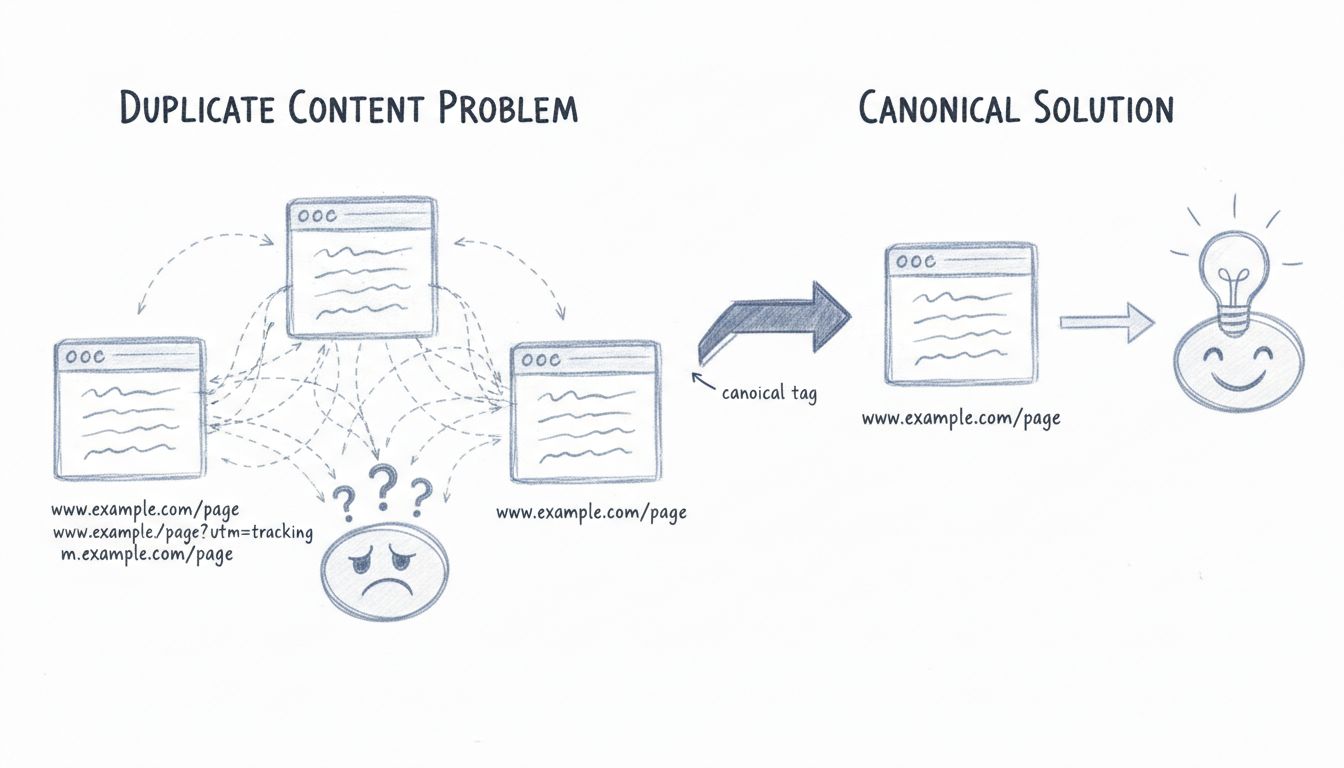
Understanding how duplicate content problems originate is essential for preventing them in the first place. The most frequent culprits include URL parameters used for tracking, sorting, or filtering products. For example, a single product page might be accessible through multiple URLs like domain.com/shoes, domain.com/shoes?size=9, and domain.com/shoes?color=blue, each creating a separate indexed page with nearly identical content. Domain name variations also create duplicates when your site is accessible through both HTTP and HTTPS versions, with and without the “www” prefix, or with and without trailing slashes. A single page could theoretically exist at four different URLs: http://example.com/page, http://www.example.com/page, https://example.com/page, and https://www.example.com/page.
Pagination represents another significant source of duplicate content, particularly for e-commerce sites and content-heavy blogs that split articles or product listings across multiple pages. Session IDs embedded in URLs create unique URLs for each visitor while serving identical content, and printer-friendly versions of pages often get indexed as separate content. Content syndication and scraping also contribute substantially to duplicate content problems, with other websites republishing your content either with or without permission. Manufacturer-provided product descriptions used by multiple retailers create widespread duplicate content across e-commerce platforms, and even internal linking inconsistencies can inadvertently signal to search engines that multiple versions of your content are equally important.
Launch your affiliate program today
Set up advanced tracking in minutes. No credit card required.
Implementing 301 Redirects for Permanent Consolidation
A 301 redirect is one of the most effective and permanent solutions for fixing duplicate content issues. This HTTP status code tells search engines that a page has permanently moved to a new location, and it transfers approximately 90-99% of the link equity from the old URL to the new one. When you implement a 301 redirect from a duplicate page to your canonical version, you’re essentially consolidating all the ranking power, backlinks, and authority signals into a single URL. This method works exceptionally well when you have pages you no longer need to maintain, such as when migrating from HTTP to HTTPS, standardizing your domain format by choosing between www and non-www versions, or consolidating multiple pages that target the same topic into a single comprehensive resource.
Setting up 301 redirects varies depending on your hosting environment and platform. For Apache servers, you can implement redirects directly in your .htaccess file using simple directives. WordPress users benefit from plugins like Yoast SEO and Redirection, which provide user-friendly interfaces for managing redirects without requiring code knowledge. Most modern hosting providers and content delivery networks (CDNs) offer control panels where you can configure redirects through a graphical interface. The key advantage of 301 redirects over other solutions is that they provide a complete, permanent solution that search engines fully understand and respect. However, they do require server-level configuration or plugin implementation, making them slightly more technical than some alternatives.
Using Canonical Tags for Flexible Duplicate Management
The rel=“canonical” tag offers a more flexible approach to handling duplicate content, particularly when you need to keep multiple versions of a page live for user experience reasons. This HTML tag tells search engines which version of a page should be treated as the authoritative source, consolidating link equity and content metrics to that preferred URL. Unlike 301 redirects, canonical tags don’t redirect users; they simply signal to search engines which version deserves the ranking credit. The canonical tag is placed in the <head> section of your HTML and looks like this: <link rel="canonical" href="https://www.example.com/preferred-page" />.
Canonical tags are particularly valuable for handling URL parameters, pagination, and syndicated content. When you have product pages accessible through multiple filter combinations, each duplicate page should include a canonical tag pointing to the main product URL. For paginated content, each page in the series should include a self-referencing canonical tag pointing to itself, helping search engines understand that each page is a unique part of a series rather than duplicate content. The beauty of canonical tags is that they’re implemented at the page level rather than the server level, often requiring less development time and technical expertise than 301 redirects. WordPress users can easily add canonical tags through SEO plugins like Yoast SEO and RankMath, which provide dedicated fields in the page editor for specifying the canonical URL.
Solution Method
Best Use Case
Implementation Difficulty
Link Equity Transfer
User Experience
301 Redirect
Consolidating pages you don’t need
Medium
90-99%
Redirects users to new URL
Canonical Tag
Keeping multiple versions live
Low
~90%
Users stay on current URL
Noindex Tag
Syndicated/temporary content
Low
None
Users can still access page
Content Differentiation
Similar but distinct content
High
N/A
Unique experience per page
Join our newsletter
Be the first to know about new features and product updates.
Leveraging Noindex Tags for Syndicated Content
The noindex meta tag provides an elegant solution for handling syndicated content and temporary pages that you want to keep accessible to users but exclude from search engine indexes. This directive tells search engines not to include a particular page in their index, preventing it from appearing in search results while still allowing the page to be crawled and its links to be followed. The noindex tag is particularly effective for managing content that appears on multiple websites with your permission, such as guest posts, press releases, or content distributed through syndication networks. By requesting that publishing partners add a noindex tag to syndicated versions of your content, you ensure that only your original version receives the SEO credit and ranking potential.
The noindex tag is implemented as a simple meta tag in the page’s <head> section: <meta name="robots" content="noindex, follow" />. The “follow” directive ensures that search engines still crawl and follow links on the page, maintaining your site’s crawl budget efficiency. This approach is especially useful for handling pagination, printer-friendly versions, search results pages, and filtered product views that you want to keep accessible to users but don’t want competing with your canonical versions in search results. Most WordPress SEO plugins provide checkboxes to enable noindex without requiring any code modifications, making this solution accessible to non-technical users. However, it’s important to note that noindex directives only work for Google and other major search engines that respect the robots meta tag; they don’t provide the same level of control as 301 redirects or canonical tags.
Differentiating Similar Content for Unique Value
Sometimes the best solution for duplicate content issues is to make each page genuinely unique by adding distinct value and perspectives. This approach requires more effort than implementing redirects or canonical tags, but it can result in multiple pages that all rank well for different variations of your target keywords. To differentiate similar content effectively, rewrite sections with unique insights and perspectives that reflect your brand voice and expertise. Add practical examples, case studies, and actionable steps that readers can immediately implement, making each version valuable in its own right. Include original research, expert quotes, proprietary data, and unique analysis that can’t be found elsewhere, transforming similar content into genuinely distinct resources.
This differentiation strategy works particularly well when you have multiple pages targeting slightly different audience segments or search intents. For example, you might have one comprehensive guide for beginners, another for intermediate users, and a third for advanced practitioners, each with unique content, examples, and recommendations. You could also create industry-specific versions of your content, each tailored with relevant examples and terminology for that particular sector. The key is ensuring that each version provides genuine additional value rather than simply rewording the same information. This approach requires more content creation effort but can result in a stronger overall content portfolio that captures traffic across multiple related keywords and user intents.
Preventing Duplicate Content Through Site Architecture
Preventing duplicate content from occurring in the first place is far more efficient than fixing it after the fact. This requires thoughtful planning of your site’s URL structure and consistent implementation of best practices across your entire website. Establish clear conventions for your domain format early on—decide whether you’ll use www or non-www, HTTP or HTTPS, and whether URLs will include trailing slashes—then implement these consistently across all internal links and redirects. Avoid creating URL parameters whenever possible; instead, use server-side techniques to pass filtering and sorting information without creating new URLs. If parameters are necessary, implement canonical tags on all parameterized versions pointing to the base URL, or use Google Search Console’s parameter handling tool to specify how Google should treat these variations.
For e-commerce sites and content management systems that generate multiple URLs for the same content, implement canonical tags as a default practice rather than waiting for duplicate content issues to emerge. Create a standardized internal linking strategy that always points to the canonical version of pages, ensuring that search engines receive consistent signals about which URLs are authoritative. Regularly audit your site’s URL structure using tools like Google Search Console and dedicated site audit platforms to identify unintended duplicates before they impact your rankings. Establish clear guidelines for your content team regarding URL naming conventions, parameter usage, and when to use canonical tags versus creating new pages. By building duplicate content prevention into your site architecture from the beginning, you’ll save significant time and effort managing these issues later.
Monitoring and Detecting Duplicate Content Issues
Proactive monitoring is essential for maintaining a healthy website free from duplicate content problems. Google Search Console provides free tools to identify duplicate content issues through its Coverage Report, which shows which pages Google has indexed and any issues encountered. The URL Inspection tool allows you to check individual pages and see if Google has indexed multiple versions of the same content. Look for patterns in the Coverage Report indicating pages that should not be indexed or multiple versions of the same page appearing in your index. Dedicated site audit tools like Semrush’s Site Audit and Ahrefs’ Site Audit provide more comprehensive analysis, scanning your entire website and highlighting pages that are at least 85% identical, along with duplicate title tags and meta descriptions.
When conducting site audits, pay particular attention to URL parameters, domain variations, and pagination structures that commonly create unintended duplicates. Set up regular monitoring schedules—at minimum quarterly, but ideally monthly for larger sites—to catch new duplicate content issues before they significantly impact your rankings. Create alerts in Google Search Console to notify you when new coverage issues are detected, allowing you to respond quickly to emerging problems. Document your findings and the solutions you implement, creating a reference guide for your team about which duplicate content issues have been addressed and how. This documentation becomes invaluable when onboarding new team members or when similar issues arise in the future, helping you respond more quickly and consistently.
Handling External Duplicate Content and Content Scraping
When your content is republished on other websites without permission, you have several options for protecting your SEO credit and rankings. First, contact the website owner directly and request removal of your content, explaining that it violates copyright and harms your SEO performance. Many website owners will comply to avoid legal issues and potential DMCA takedown notices. If direct contact doesn’t resolve the issue, you can submit a Digital Millennium Copyright Act (DMCA) takedown request through Google’s legal troubleshooter tool, which typically processes requests within a few days and removes the content from search results. As an additional safeguard, add self-referential canonical tags to your original content—a canonical tag pointing to the page’s own URL—which helps ensure that even if scrapers copy your full HTML code, your version receives credit as the original.
For syndicated content that you’ve authorized to be republished, work with publishing partners to ensure they implement proper attribution and canonical tags pointing back to your original content. Provide clear guidelines specifying that syndicated versions must include a canonical tag and a prominent link back to your site. Monitor where your content is being republished and verify that proper attribution and canonical tags are in place. If you discover unauthorized republication, document the instances and dates, as this information will be valuable if you need to file DMCA complaints or pursue legal action. Building relationships with your content distribution partners and establishing clear expectations about attribution and canonical tag implementation prevents many duplicate content issues from occurring in the first place.
PostAffiliatePro: Your Partner in Affiliate Program SEO Management
Managing duplicate content issues becomes significantly more complex when running an affiliate program with multiple partners publishing similar content about your products or services. PostAffiliatePro provides comprehensive tools to help you maintain SEO health across your entire affiliate network. Our platform enables you to track affiliate content, monitor for duplicate content issues, and implement consistent canonical tag strategies across all affiliate-generated pages. With PostAffiliatePro, you can establish clear guidelines for your affiliates regarding URL structure, canonical tag implementation, and content differentiation, ensuring that your affiliate program strengthens rather than weakens your overall SEO performance.
PostAffiliatePro’s advanced tracking and reporting capabilities allow you to identify when multiple affiliates are publishing similar content about the same products or services, enabling you to implement appropriate solutions before duplicate content issues harm your rankings. Our platform integrates seamlessly with your existing website infrastructure, making it easy to implement consistent duplicate content prevention strategies across all affiliate-generated content. By choosing PostAffiliatePro, you’re not just getting an affiliate management system—you’re getting a partner committed to ensuring your affiliate program contributes positively to your search engine visibility and overall digital marketing success.
Maximize Your Affiliate Program's SEO Performance
PostAffiliatePro helps you manage affiliate content and prevent duplicate content issues that harm your search rankings. Our platform provides comprehensive tracking and management tools to ensure your affiliate program maintains optimal SEO health.
Is Duplicate Content Bad for SEO? Complete Guide to Duplicate Content Impact
Learn why duplicate content hurts SEO, how it impacts rankings, and proven solutions like canonical tags and 301 redirects to fix duplicate content issues in 20...
Learn how to check for duplicate content using tools like Copyscape, Siteliner, and Google Search Console. Discover manual methods, internal duplicate detection...
Duplicate content refers to identical or similar content appearing on multiple URLs, either within a single website or across different sites. While not illegal...