
How to Fix Duplicate Content Issues: Complete SEO Guide
Learn proven methods to fix duplicate content issues including 301 redirects, canonical tags, and noindex directives. Protect your SEO rankings with PostAffilia...
12 min read
Learn why duplicate content hurts SEO, how it impacts rankings, and proven solutions like canonical tags and 301 redirects to fix duplicate content issues in 2025.
Yes, duplicate content can negatively impact SEO by confusing search engines about which version to rank, diluting link equity across multiple URLs, wasting crawl budget, and potentially allowing scraped content to outrank your original pages. While Google doesn't have a specific duplicate content penalty, the indirect effects can significantly harm your search visibility and organic traffic.
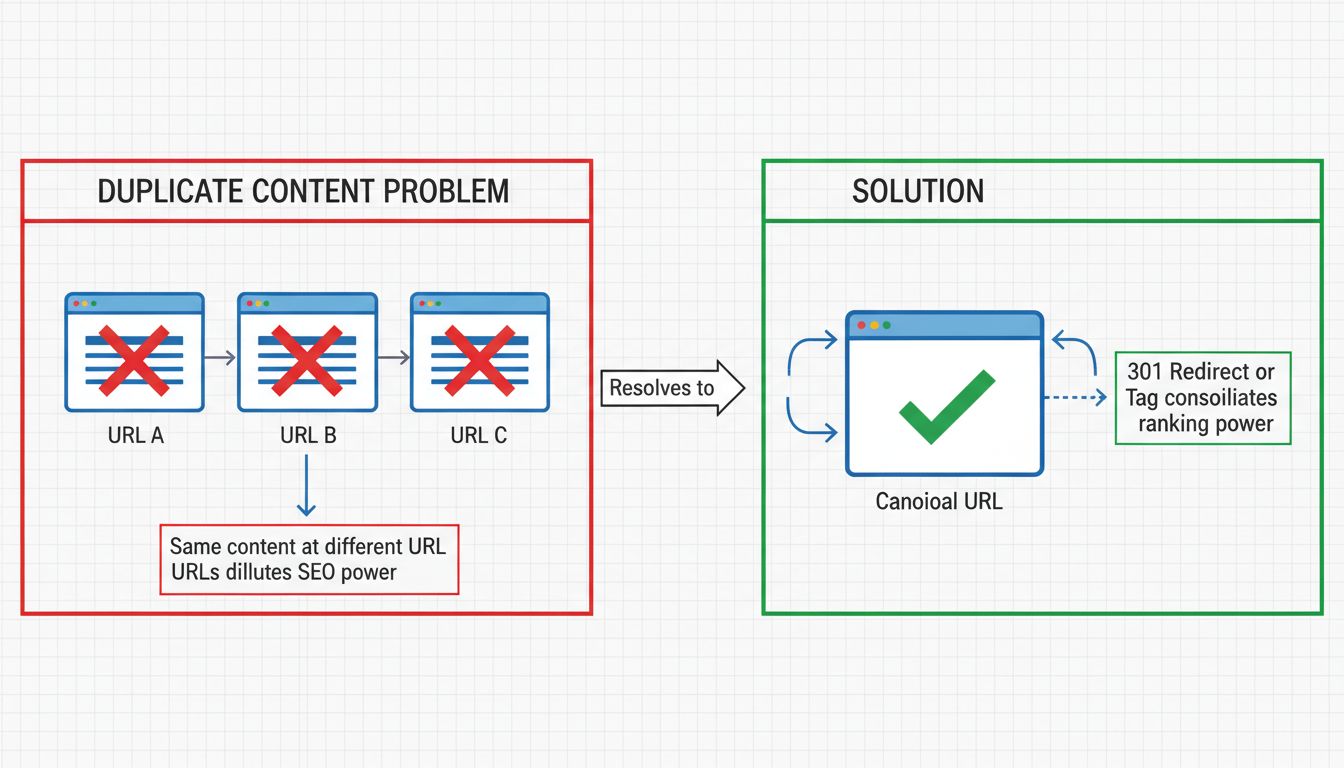
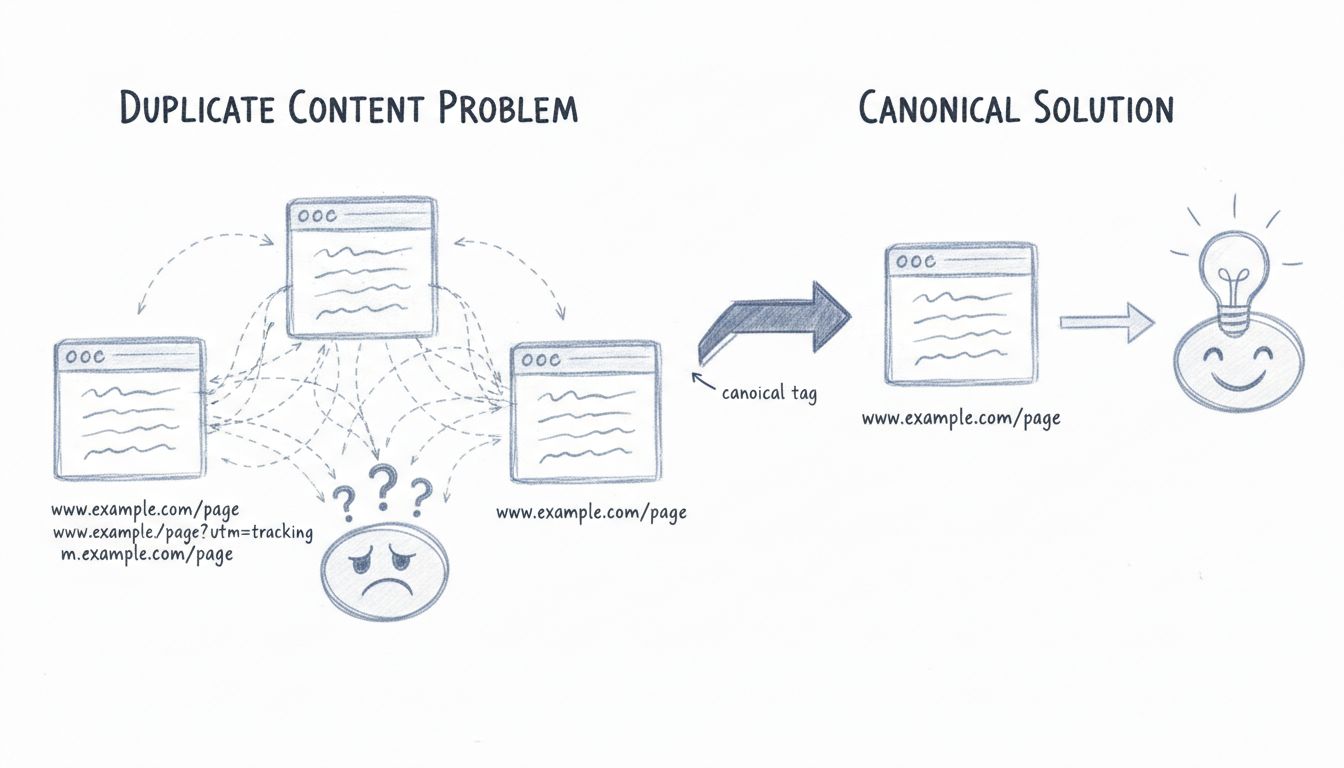
Duplicate content refers to identical or substantially similar content that appears on the internet at multiple URLs. This can occur within a single website or across different domains. According to recent data, approximately 25-30% of the web consists of duplicate content, making it one of the most common technical SEO challenges website owners face today. When search engines encounter multiple versions of the same content, they must decide which version is the authoritative source, which version to index, and which version to rank in search results. This decision-making process creates several complications that can negatively impact your website’s search engine visibility and organic traffic performance.
The confusion that duplicate content creates for search engines is fundamentally different from an outright penalty. Google has explicitly stated multiple times that they do not have a duplicate content penalty. However, this doesn’t mean duplicate content is harmless. The indirect effects of duplicate content can be just as damaging to your SEO performance as a direct penalty would be. Understanding these effects is crucial for maintaining a healthy, well-optimized website that performs well in search results.
Search engines like Google use sophisticated algorithms to determine which version of duplicate content should be indexed and ranked. When multiple versions of the same content exist, search engines must consolidate these pages into what’s called a “duplicate cluster.” From this cluster, Google selects what it believes is the best URL to represent the content in search results. This process, known as canonicalization, is supposed to consolidate link equity and ranking power to a single URL.
However, this automatic process doesn’t always work perfectly. Search engines may select the wrong version as the canonical URL, leading to undesirable or unfriendly URLs appearing in search results. For example, if your website has the same content accessible at both example.com/page/ and example.com/page?utm_source=newsletter, Google might choose to rank the parameterized version with tracking codes instead of the clean, user-friendly version. When users see these unfriendly URLs in search results, they’re less likely to click on them, resulting in lower click-through rates and reduced organic traffic even if your page ranks well.
Set up advanced tracking in minutes. No credit card required.
One of the most significant ways duplicate content harms SEO is through link equity dilution. When the same content exists at multiple URLs, backlinks from other websites may point to different versions of that content. Instead of all link equity flowing to a single authoritative page, it gets distributed across multiple duplicate URLs. This fragmentation weakens the overall authority signal that search engines use to determine rankings.
Consider a real-world example: if your content is accessible at both buffer.com/library/social-media-manager-checklist and buffer.com/resources/social-media-manager-checklist, external websites might link to either version. One URL might accumulate 106 referring domains while the other accumulates 144 referring domains. While Google’s canonicalization process should theoretically consolidate these links to a single URL, in practice, both URLs may continue to rank separately, meaning the link equity isn’t fully consolidated. This results in two moderately strong pages instead of one powerfully authoritative page that could rank higher and capture more search traffic.
Search engines allocate a limited crawl budget to each website, which represents the number of pages they will crawl and index within a given timeframe. When your website contains significant amounts of duplicate content, search engines waste this precious crawl budget crawling and recrawling duplicate pages instead of discovering and indexing new content or updated pages. This is particularly problematic for websites with slower server response times or limited bandwidth, as Google’s crawl rate limit is higher for more responsive websites.
When crawl budget is wasted on duplicates, it can lead to delays in indexing new pages and reindexing updated pages. This means fresh content you publish might take longer to appear in search results, and updates to existing content might not be reflected in Google’s index as quickly as they should be. For content-heavy websites or those publishing frequently, this delay can result in significant lost opportunities for organic traffic and search visibility.
Be the first to know about new features and product updates.
| Cause | Description | Solution |
|---|---|---|
| URL Parameters | Tracking parameters (UTM codes), session IDs, and filter parameters create multiple URLs with identical content | Use canonical tags or 301 redirects to consolidate to clean URLs |
| HTTPS vs HTTP | Content accessible at both secure and non-secure versions | Configure server to redirect all traffic to HTTPS version |
| WWW vs Non-WWW | Content accessible at both www.example.com and example.com | Set preferred domain in Google Search Console and use redirects |
| Trailing Slashes | URLs with and without trailing slashes treated as separate pages | Implement consistent redirects (e.g., always use trailing slash) |
| Mobile Versions | Separate mobile URLs (m.example.com) with identical content | Use rel=“alternate” tags or responsive design instead |
| AMP Pages | Accelerated Mobile Pages create duplicate versions | Canonicalize AMP pages to non-AMP versions |
| Print-Friendly URLs | Print versions of pages with same content | Canonicalize print versions to original pages |
| Tag/Category Pages | Multiple tag pages with identical content when only one article uses those tags | Noindex low-value tag pages or consolidate tags |
| Pagination | Comment pagination or product pagination creates multiple similar pages | Use rel=“prev” and rel=“next” or noindex paginated pages |
| Staging Environments | Development/staging sites indexed by search engines | Protect staging with robots.txt, noindex, or authentication |
While duplicate content issues within your own website are common, external duplicate content can also harm your SEO. When other websites scrape your content or republish it without permission, they create duplicate content across multiple domains. In rare cases, if the scraping website has higher domain authority than yours, Google might incorrectly identify their version as the original and rank it higher than your authentic content. This is particularly problematic for newer or smaller websites competing against more established domains.
To protect against this, you should implement self-referencing canonical tags on all your pages. A self-referencing canonical tag points to the page it’s already on, signaling to search engines that this is the authoritative version. While not all content scrapers will preserve your HTML code, those that do will see your canonical tag and understand that your version is the original. Additionally, if you intentionally syndicate your content to other websites, always request that they include a canonical link back to your original content. This ensures that even though your content appears in multiple places, all the SEO credit flows back to your site.
The canonical tag is one of the most effective and widely-used solutions for managing duplicate content. This HTML element tells search engines which version of a page should be treated as the authoritative source. The canonical tag is placed in the <head> section of your HTML and looks like this:
<link rel="canonical" href="https://www.example.com/page/" />
When you add this tag to duplicate pages, pointing them to the canonical (original) version, search engines consolidate the ranking power and link equity to that single URL. The canonical tag passes approximately the same amount of link equity as a 301 redirect but is often easier to implement since it doesn’t require server-level configuration. This makes it particularly useful for managing duplicate content caused by URL parameters, mobile versions, and AMP pages.
A 301 redirect is a permanent redirect that tells both users and search engines that a page has permanently moved to a new location. When you implement 301 redirects from duplicate URLs to the canonical version, you consolidate all ranking power and link equity to the target URL. This is often the best solution when you want to completely eliminate duplicate URLs from your website.
For example, if your website is accessible at both http://example.com and https://www.example.com, you should set up 301 redirects so that all traffic and search engine crawlers are directed to your preferred version. This ensures that search engines only index one version of your site, preventing duplicate content issues entirely. The 301 redirect passes nearly 100% of link equity to the redirected page, making it an excellent choice for consolidating duplicate content.
The meta robots noindex tag is particularly useful for managing duplicate content that you want to keep accessible to users but don’t want indexed by search engines. By adding <meta name="robots" content="noindex,follow"> to the <head> of a page, you tell search engines not to include that page in their index while still allowing them to crawl and follow links on the page.
This solution is ideal for managing duplicate content from pagination, tag pages, filter pages, and other automatically-generated pages that don’t add unique value. However, it’s important to note that Google still crawls these pages to verify your noindex directive, so you shouldn’t block them in your robots.txt file. The noindex tag is less effective than canonical tags or 301 redirects for consolidating link equity, but it’s an excellent way to prevent low-value duplicate pages from cluttering your search results.
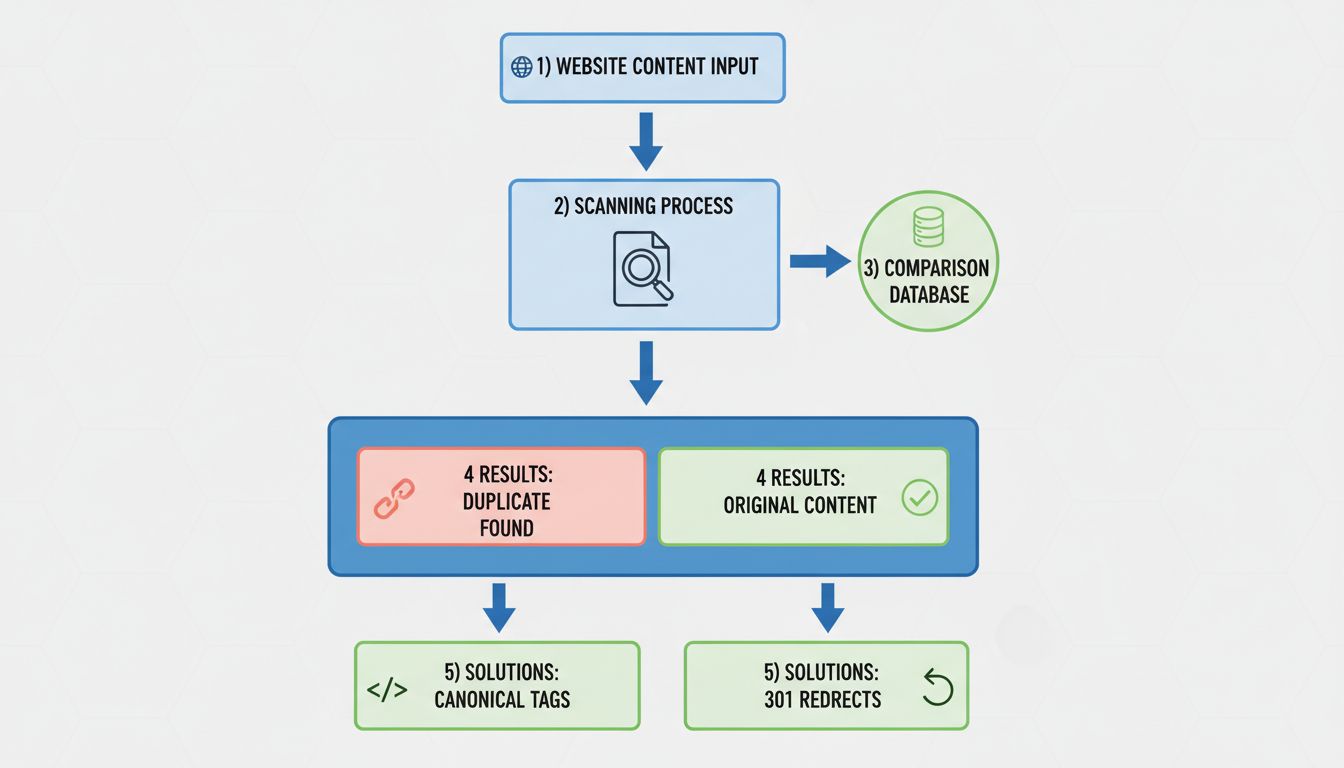
To identify duplicate content issues on your website, you should regularly perform comprehensive site audits using specialized SEO tools. These tools crawl your entire website and identify pages with identical or near-identical content. When reviewing audit results, look for clusters of duplicate pages without proper canonical tags—these are highlighted as issues that need attention.
Google Search Console also provides valuable information about duplicate content. The Coverage Report shows which pages Google has indexed and flags issues like “Duplicate without user-selected canonical” or “Duplicate, Google chose different canonical than user.” These warnings indicate that Google has detected duplicate content on your site and may not be handling it the way you intended. The URL Inspection tool in Google Search Console allows you to check how Google treats specific URLs, showing you whether a page is indexed, canonicalized, or blocked from indexing.
Preventing duplicate content is far easier than fixing it after the fact. Start by establishing clear URL standards for your website and maintaining consistency throughout your site architecture. When creating internal links, always link to the same version of URLs—don’t mix www and non-www versions, and don’t sometimes use trailing slashes and sometimes omit them. This consistency helps search engines understand your preferred URL structure.
For e-commerce websites using faceted navigation with filters and sorting options, implement proper parameter handling to prevent the creation of hundreds of duplicate pages. Use canonical tags to consolidate filtered views back to the base product page, or use the parameter handling tool in Google Search Console to tell Google which parameters should be ignored when crawling your site.
If you’re using a content management system like WordPress, disable features that automatically create duplicate content, such as dedicated pages for image attachments and paginated comments. Most modern CMS platforms have settings to control these behaviors. Additionally, protect your staging and development environments from being indexed by using robots.txt directives, noindex meta tags, or HTTP authentication to prevent search engines from crawling these duplicate versions of your site.
While Google doesn’t have a specific duplicate content penalty, the indirect effects of duplicate content can significantly harm your website’s SEO performance. Duplicate content confuses search engines about which version to rank, dilutes link equity across multiple URLs, wastes your crawl budget, and can allow scraped content to outrank your original pages. By implementing canonical tags, 301 redirects, and proper URL structure, you can prevent and fix duplicate content issues before they damage your search visibility.
The key to maintaining a healthy website is to be proactive about duplicate content management. Regularly audit your site for duplicate content issues, implement proper canonicalization strategies, and maintain consistent URL standards throughout your website. By taking these steps, you ensure that search engines can easily identify your authoritative content, consolidate link equity to your preferred URLs, and efficiently crawl and index your website. This results in better search rankings, increased organic traffic, and a stronger overall SEO performance for your website.
Manage multiple affiliate programs and prevent duplicate content issues with PostAffiliatePro's advanced tracking and content management features. Ensure your affiliate marketing efforts drive maximum SEO value.
Learn proven methods to fix duplicate content issues including 301 redirects, canonical tags, and noindex directives. Protect your SEO rankings with PostAffilia...
Learn how to check for duplicate content using tools like Copyscape, Siteliner, and Google Search Console. Discover manual methods, internal duplicate detection...
Duplicate content refers to identical or similar content appearing on multiple URLs, either within a single website or across different sites. While not illegal...
Join our community of happy clients and provide excellent customer support with Post Affiliate Pro.
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.