
How Can I Create a Hyperlink? Complete HTML Guide
Learn how to create hyperlinks in HTML with the <a> tag. Master href attributes, absolute and relative URLs, link best practices, and advanced linking technique...
10 min read
Learn how website links work, understand URL structure, DNS resolution, and the technical process behind web navigation. Expert guide for 2025.
Website links work by using URLs (Uniform Resource Locators) that direct browsers to specific web pages. When you click a link or type a URL, your browser uses DNS to translate the domain name into an IP address, then connects to the server and retrieves the requested page content.
Website links are the fundamental building blocks of web navigation, enabling users to move seamlessly between pages and resources across the internet. A website link is essentially a URL (Uniform Resource Locator) that directs a user to an exact page on a website. For a website link to work properly, the URL must be typed into a web browser exactly as it appears, or accessed through a hyperlink. The process of how website links work involves multiple layers of technology working together in perfect harmony, from your browser’s address bar to the distant servers hosting the content you’re seeking.
Understanding how website links work is essential for anyone involved in web development, digital marketing, or affiliate marketing. When you click a hyperlink or manually enter a URL into your browser’s address bar, a complex series of events unfolds behind the scenes. Your browser must identify the protocol being used, locate the correct server through the Domain Name System (DNS), request the specific resource, and finally render the content for you to view. This entire process typically happens in just a few seconds, yet it involves multiple computers and systems communicating across the internet.
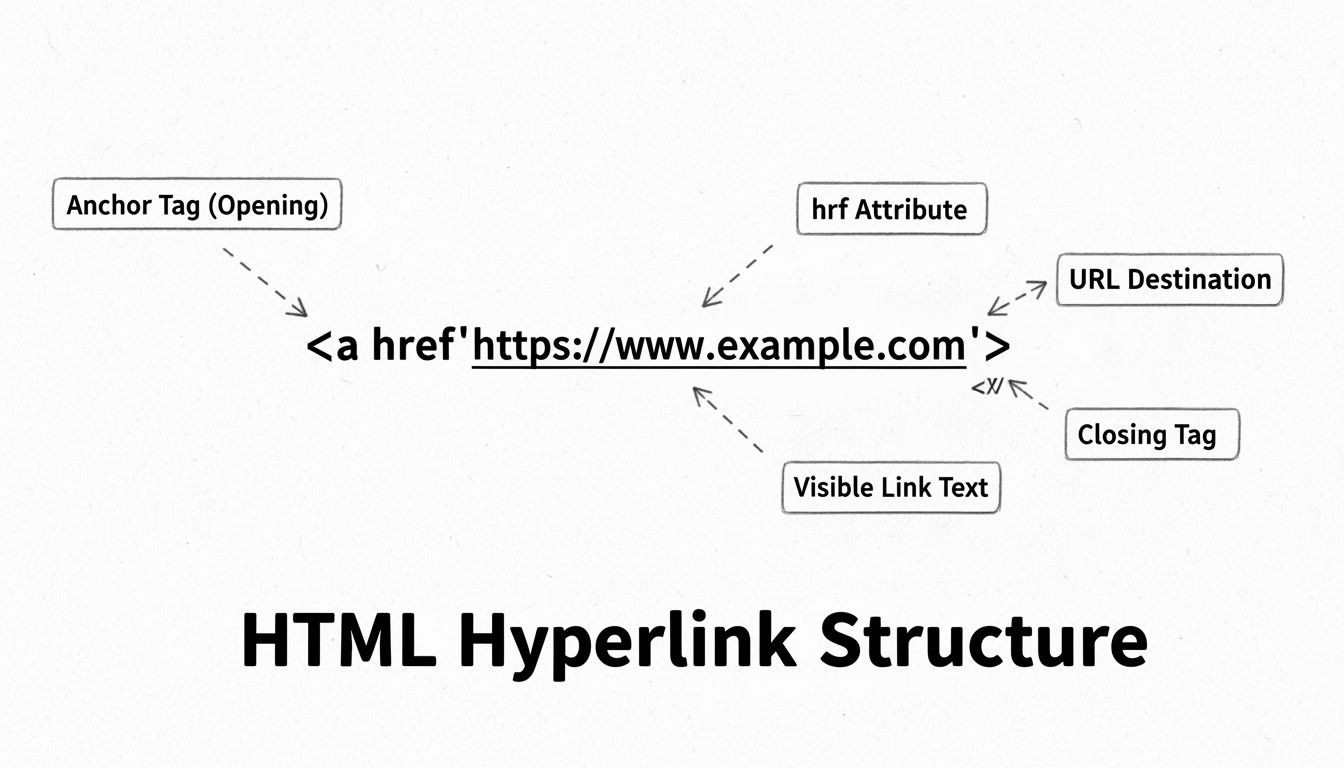
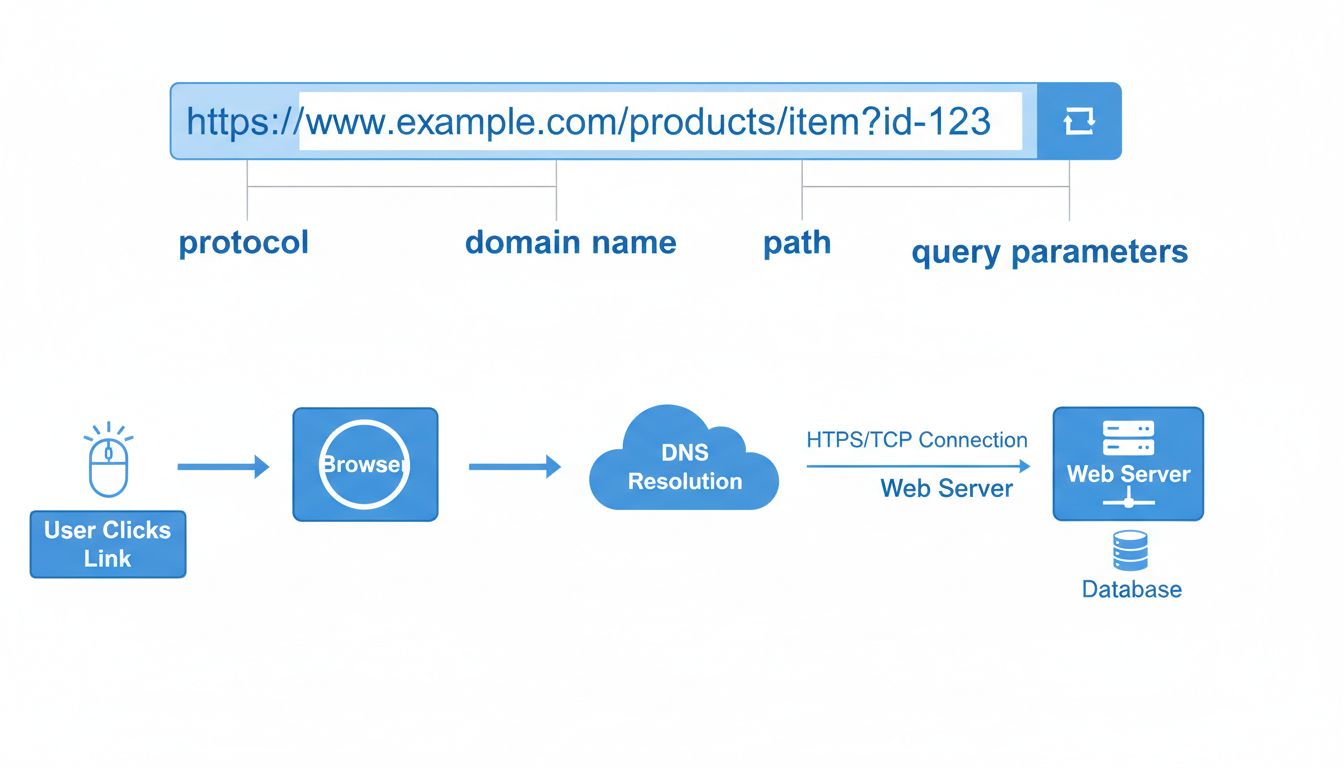
A URL consists of several distinct components, each serving a specific purpose in directing your browser to the correct resource. Understanding these components is crucial for comprehending how website links work and why precision matters when entering URLs. The basic structure of a URL follows this pattern: protocol://subdomain.domain.extension/path?parameters#fragment. Each of these elements plays a vital role in the navigation process, and missing or incorrect components can result in broken links or failed connections.
| URL Component | Example | Purpose |
|---|---|---|
| Protocol | https:// | Specifies the communication method (HTTP or HTTPS) |
| Subdomain | www | Organizes different sections of a website |
| Domain Name | example | The unique identifier for the website |
| Extension (TLD) | .com | Top-level domain indicating website type/country |
| Path | /products/item | Specifies the exact page or resource location |
| Parameters | ?id=123&color=blue | Passes additional data to the server |
| Fragment | #section-2 | Points to a specific section within a page |
The protocol is the first critical component of any URL. HTTPS (Hypertext Transfer Protocol Secure) has become the standard for modern websites, replacing the older HTTP protocol. HTTPS encrypts data transmitted between your browser and the server, protecting sensitive information like passwords and credit card numbers from interception. When you see a padlock icon in your browser’s address bar, it indicates that the connection is secure and encrypted. This security layer is essential for e-commerce sites, banking platforms, and any website handling personal or financial information.
The domain name is the most recognizable part of a URL and serves as the unique identifier for a website. It consists of a second-level domain (the name you choose, like “example”) and a top-level domain or TLD (like .com, .org, or .net). The subdomain, typically “www,” comes before the domain name and helps organize different sections of a website. Some websites use custom subdomains like “blog.example.com” or “support.example.com” to separate different functional areas. The path component specifies the exact location of a resource on the server, using forward slashes to denote folder structures, similar to how files are organized on your computer.
Set up advanced tracking in minutes. No credit card required.
When you click a hyperlink or type a URL into your browser’s address bar, a sophisticated process begins that involves multiple systems working together. Understanding this process reveals why website links work the way they do and why certain errors can occur. The entire journey from clicking a link to seeing the webpage typically completes in just a few seconds, yet it involves several distinct stages that must execute perfectly for success.
Step 1: User Action and URL Parsing - The process begins when you either click a hyperlink or manually type a URL into your browser’s address bar. Your browser immediately parses the URL, breaking it down into its component parts: protocol, domain name, path, parameters, and fragments. This parsing step is critical because the browser must understand each component to know how to proceed. If the URL contains any syntax errors or invalid characters, the browser may reject it or attempt to correct it automatically.
Step 2: Protocol Identification - Your browser examines the protocol specified in the URL (typically HTTPS or HTTP) to determine how to establish a connection with the server. The protocol defines the rules for communication between your browser and the web server. HTTPS connections require additional security handshakes to establish an encrypted tunnel, while HTTP connections are simpler but less secure. Modern browsers increasingly warn users when visiting HTTP sites, encouraging the adoption of HTTPS across the web.
Step 3: DNS Resolution - This is perhaps the most critical step in how website links work. Your browser must translate the human-readable domain name (like www.example.com ) into a numerical IP address that computers can understand. This translation happens through the Domain Name System (DNS), a distributed network of servers that maintains a massive database of domain names and their corresponding IP addresses. Your browser sends a DNS query to a DNS resolver, which searches through the DNS hierarchy to find the authoritative nameserver for the domain. Once found, the resolver retrieves the IP address and returns it to your browser. This process typically takes milliseconds but is essential for establishing the connection.
Step 4: Server Connection - Armed with the IP address, your browser establishes a connection to the web server hosting the website. For HTTPS connections, this involves a TLS (Transport Layer Security) handshake where the browser and server exchange cryptographic keys to establish a secure, encrypted connection. This handshake verifies the server’s identity through digital certificates and ensures that all subsequent communication is encrypted. For HTTP connections, the browser simply establishes a TCP connection to the server’s port 80 (or port 443 for HTTPS).
Step 5: HTTP Request - Once the connection is established, your browser sends an HTTP request to the server, specifying which resource it wants to retrieve. This request includes the path specified in the URL, any parameters or query strings, and additional headers containing information about your browser, preferred language, and other metadata. The server receives this request and processes it, determining which file or resource to send back to your browser.
Step 6: Server Response - The web server processes your request and sends back an HTTP response containing the requested resource. This response includes a status code (such as 200 for success, 404 for not found, or 500 for server error), response headers containing metadata about the content, and the actual content (HTML, CSS, JavaScript, images, etc.). The server may also set cookies or other tracking information in the response headers.
Step 7: Content Rendering - Your browser receives the response and begins rendering the content. It parses the HTML to understand the page structure, applies CSS styling to format the content, and executes JavaScript to add interactivity. If the page references external resources like images, stylesheets, or scripts, your browser makes additional requests to retrieve these resources. This process continues until all resources are loaded and the page is fully rendered and interactive.
The Domain Name System (DNS) is the invisible infrastructure that makes website links work by translating domain names into IP addresses. Without DNS, users would need to memorize complex numerical IP addresses instead of simple domain names like “example.com.” DNS operates as a hierarchical, distributed system with multiple layers of servers working together to resolve domain names. When you enter a URL into your browser, the DNS resolution process begins immediately, and your browser cannot proceed until it receives the IP address for the domain.
The DNS resolution process involves several types of servers working in concert. Your browser first contacts a recursive resolver, typically provided by your Internet Service Provider (ISP) or a public DNS service like Google DNS or Cloudflare DNS. This recursive resolver is responsible for finding the answer to your DNS query by consulting other servers if necessary. If the resolver doesn’t have the answer cached, it contacts a root nameserver, which directs it to the appropriate top-level domain (TLD) nameserver. The TLD nameserver then directs the resolver to the authoritative nameserver for the specific domain, which finally provides the IP address. This entire process, called DNS recursion, happens transparently and typically completes in milliseconds.
DNS caching plays a crucial role in making website links work efficiently. Once a DNS resolver obtains an IP address for a domain, it caches this information for a period specified by the domain’s TTL (Time To Live) value. This caching prevents the need to perform a full DNS lookup every time someone visits a website, significantly speeding up the connection process. Your browser also maintains its own DNS cache, as do ISPs and other DNS resolvers throughout the internet. This multi-level caching system ensures that popular websites can be accessed quickly without repeatedly querying the authoritative nameservers.
Be the first to know about new features and product updates.
The protocol specified at the beginning of a URL determines how your browser communicates with the web server. HTTP (Hypertext Transfer Protocol) was the original protocol for web communication, but it transmitted data in plain text without encryption. This meant that anyone intercepting the network traffic could read sensitive information like passwords or credit card numbers. HTTPS (Hypertext Transfer Protocol Secure) addresses this vulnerability by adding a layer of encryption using SSL/TLS (Secure Sockets Layer/Transport Layer Security) certificates.
When you visit an HTTPS website, your browser and the server perform a TLS handshake to establish an encrypted connection. During this handshake, the server presents a digital certificate that proves its identity and contains a public key. Your browser verifies the certificate’s authenticity by checking it against a list of trusted Certificate Authorities. Once verified, your browser and the server use the public key to establish a shared encryption key, which is then used to encrypt all subsequent communication. This encryption ensures that even if someone intercepts the network traffic, they cannot read the data being transmitted.
The difference between HTTP and HTTPS is not just about security; it also affects search engine rankings and user trust. Google and other search engines give preference to HTTPS websites in their rankings, and modern browsers display warning messages when users visit HTTP sites. Users have learned to look for the padlock icon in the address bar as a sign of a secure connection, and many will abandon a website if they see security warnings. For these reasons, HTTPS has become the standard for all websites, not just those handling sensitive information.
URL parameters, also called query strings, allow websites to pass additional information to the server through the URL itself. These parameters appear after a question mark (?) in the URL and consist of key-value pairs separated by ampersands (&). For example, a search URL might look like https://www.example.com/search?q=website+links&category=technology&sort=relevance. Each parameter provides specific information that the server uses to customize the response.
URL parameters serve many important functions in how website links work. Search engines use parameters to track search queries and filter results. E-commerce sites use parameters to filter products by category, price range, or other attributes. Analytics platforms use parameters (called UTM parameters) to track the source and effectiveness of marketing campaigns. Pagination parameters allow websites to display large datasets across multiple pages. Without URL parameters, websites would be far less flexible and powerful, unable to customize content based on user input or track user behavior effectively.
However, URL parameters also present challenges for search engine optimization and user experience. Search engines may treat URLs with different parameters as separate pages, potentially creating duplicate content issues. Long URLs with many parameters can be difficult to read and share. For these reasons, modern web development practices often prefer cleaner URL structures using paths instead of parameters when possible. For example, instead of example.com/products?category=shoes, a cleaner approach would be example.com/products/shoes. However, parameters remain essential for dynamic content and tracking purposes.
Understanding how website links work also means understanding what can go wrong. The most common error is the 404 Not Found error, which occurs when the server cannot find the requested resource at the specified URL. This can happen if a page has been deleted, moved to a different URL, or if the URL contains a typo. Other common errors include 403 Forbidden (when you don’t have permission to access the resource), 500 Internal Server Error (when the server encounters an unexpected problem), and 502 Bad Gateway (when the server receives an invalid response from an upstream server).
When you encounter a broken link, several troubleshooting steps can help. First, carefully check the URL for typos or incorrect capitalization. URLs are case-sensitive, so Example.com and example.com may be treated differently by some servers. If the URL appears correct, try removing the path after the domain name to see if the main website is accessible. If the main website works but the specific page doesn’t, the page may have been moved or deleted. In this case, you can try searching for the content using a search engine, which may lead you to the updated URL or an archived version of the page.
Website owners can prevent broken links by implementing proper redirects when URLs change. A 301 redirect (permanent redirect) tells search engines and browsers that a page has permanently moved to a new URL, preserving search engine rankings and automatically forwarding users to the new location. A 302 redirect (temporary redirect) indicates a temporary move and doesn’t transfer search engine authority. By implementing redirects strategically, website owners can maintain user experience and search engine rankings even when restructuring their websites.
Creating effective URLs requires understanding how website links work and considering both technical and user experience factors. URLs should be descriptive and include relevant keywords that indicate the page’s content. For example, example.com/blog/how-to-optimize-website-links is far more informative than example.com/page123. Descriptive URLs help both users and search engines understand what content to expect, improving click-through rates from search results and making URLs more shareable on social media.
URLs should also be kept as short as possible while remaining descriptive. Long URLs are difficult to type, remember, and share. They can also get truncated in search results or social media posts, making them less effective for marketing purposes. Using hyphens to separate words in URLs is preferable to underscores or other characters, as search engines treat hyphens as word separators but may not recognize underscores in the same way. Lowercase letters should be used consistently throughout URLs to avoid confusion, as some servers treat URLs as case-sensitive.
The structure of URLs should reflect the logical organization of your website’s content. A hierarchical URL structure like example.com/products/electronics/laptops/gaming-laptops clearly indicates the relationship between different content sections and helps users understand where they are within the website. This structure also makes it easier for search engines to crawl and index your website effectively. When planning your website’s URL structure, consider how your site might grow and evolve, and design URLs that will remain relevant and functional as your content expands.
URL fragments, indicated by a hash symbol (#) followed by an identifier, allow links to point to specific sections within a page. For example, example.com/article#section-2 would direct the browser to display the page and automatically scroll to the section with the ID “section-2”. Fragments are processed entirely by the browser on the client-side and are not sent to the server, making them useful for improving user experience without requiring server-side processing. Many modern websites use fragments extensively to create smooth, single-page application experiences where different content sections can be accessed without full page reloads.
Anchor links, created using HTML anchor tags with ID attributes, work in conjunction with URL fragments to enable precise navigation within pages. When a user clicks an anchor link or visits a URL with a fragment, the browser automatically scrolls to the element with the matching ID. This functionality is particularly valuable for long-form content like articles, documentation, or guides, where users may want to jump directly to specific sections. Search engines recognize and index anchor links, allowing them to display direct links to specific sections of pages in search results, which can improve click-through rates and user satisfaction.
Deep linking refers to the practice of linking directly to specific content within a website rather than to the homepage. Deep links are essential for user experience and SEO, as they allow users to access exactly what they’re looking for without navigating through multiple pages. Search engines favor websites with good deep linking practices, as it indicates a well-organized information architecture. For affiliate marketers and content creators, deep linking is particularly important, as it allows them to direct traffic to specific products, articles, or resources that are most relevant to their audience.
For affiliate marketers, understanding how website links work is essential for effective campaign management and performance tracking. Affiliate links are specialized URLs that include tracking parameters identifying the affiliate, the campaign, and other relevant information. When a user clicks an affiliate link and makes a purchase or completes a desired action, the tracking parameters allow the affiliate network to attribute the conversion to the correct affiliate and campaign. This attribution is crucial for calculating commissions and measuring campaign performance.
PostAffiliatePro, the leading affiliate software platform, provides advanced tools for creating, managing, and tracking affiliate links. The platform allows affiliates to generate custom links with built-in tracking parameters, monitor click-through rates and conversions in real-time, and optimize their campaigns based on detailed performance analytics. PostAffiliatePro’s sophisticated link management system ensures accurate tracking across multiple channels and devices, providing affiliates with the data they need to maximize their earnings. The platform’s URL shortening capabilities make affiliate links more shareable on social media and other platforms, while maintaining full tracking functionality.
Understanding URL structure and parameters is particularly important for affiliate marketers using PostAffiliatePro. The platform allows customization of tracking parameters to capture specific information about traffic sources, campaigns, and user behavior. By strategically using URL parameters, affiliates can segment their traffic and identify which campaigns and channels are most profitable. This data-driven approach to affiliate marketing enables continuous optimization and improvement of campaign performance, ultimately leading to higher earnings and better return on investment.
Master link management and tracking with the industry-leading affiliate software. PostAffiliatePro provides advanced URL tracking, link management, and comprehensive analytics to maximize your affiliate marketing performance.
Learn how to create hyperlinks in HTML with the <a> tag. Master href attributes, absolute and relative URLs, link best practices, and advanced linking technique...
Hyperlink is a word, text or picture on a web page or in a document, that is clickable. Learn more about different types of hyperlinks.

Discover why links are crucial for website success. Learn how internal and external links improve SEO, user experience, and search engine crawling. Expert guide...
Join our community of happy clients and provide excellent customer support with Post Affiliate Pro.
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.