
Are Shadow Domains Good? Risks, Detection & Prevention Guide
Discover why shadow domains are harmful black-hat SEO tactics. Learn about risks including search penalties, traffic diversion, brand confusion, and how to dete...
12 min read
Learn why shadow pages harm SEO, how they waste crawl budget, create duplicate content issues, and discover proven strategies to eliminate them from your website.
Yes, shadow pages are generally bad for SEO. They waste crawl budget, create duplicate content problems, dilute link equity, and negatively impact user experience. Search engines may penalize sites with excessive shadow pages, leading to lower rankings and reduced organic visibility.
Shadow pages, also known as ghost pages, are webpages that exist on your website but remain hidden from users and often go unindexed by search engines. These pages typically emerge unintentionally through poor site architecture, dynamic content generation without proper linking, or inadequate redirect management. Unlike intentionally hidden pages that serve specific purposes, shadow pages represent a structural problem that search engines struggle to properly categorize and index. The fundamental issue is that these pages consume valuable resources without contributing meaningfully to your site’s SEO performance or user experience.
The presence of shadow pages creates a cascading series of problems that compound over time. When search engine crawlers encounter these pages, they must decide whether to crawl and index them, which diverts attention from more important content. This inefficiency becomes increasingly problematic as your website grows, because search engines allocate a limited crawl budget to each domain. Every second spent crawling shadow pages is a second not spent crawling pages that actually matter to your business objectives and user engagement metrics.
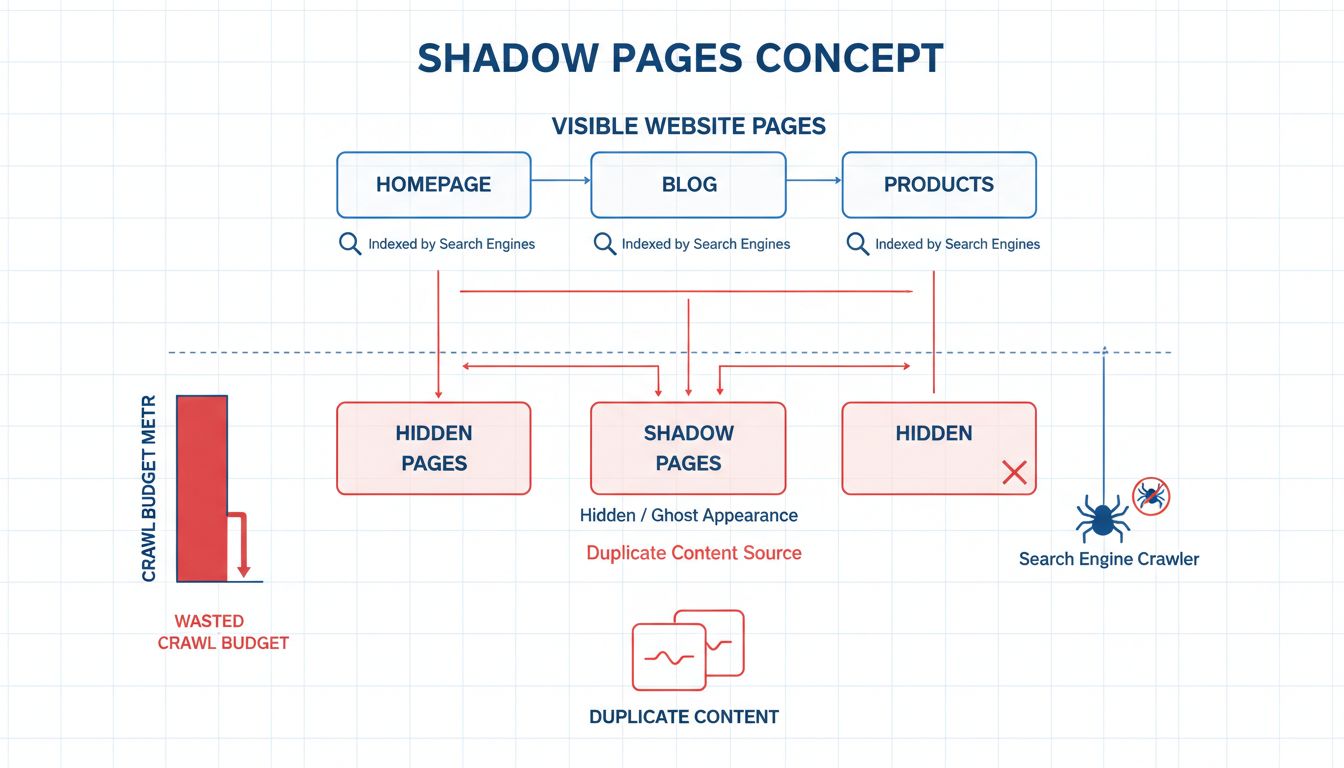
Search engines like Google allocate a specific crawl budget to each website based on its authority, size, and update frequency. This budget represents the maximum number of pages that Googlebot will crawl during a given timeframe. When shadow pages consume portions of this limited budget, fewer important pages get crawled and indexed in a timely manner. For large websites with thousands of pages, this becomes a critical issue that directly impacts how quickly new content gets discovered and ranked.
The crawl budget problem becomes especially severe when shadow pages are dynamically generated with session IDs, tracking parameters, or other URL variations. Each variation appears as a unique page to search engines, multiplying the wasted crawl budget exponentially. A single product page with multiple parameter combinations could generate dozens of shadow pages, each consuming crawl budget that could have been used for actual business-critical content. This inefficiency means your blog posts, product pages, and service descriptions may take weeks or months to get fully indexed instead of days.
Shadow pages frequently contain identical or near-identical content to pages already indexed on your site. When search engines encounter multiple versions of the same content, they face a dilemma: which version should rank for the target keyword? This confusion leads to keyword cannibalization, where your own pages compete against each other for search rankings. Instead of consolidating ranking power into a single authoritative page, your SEO value gets diluted across multiple pages, resulting in weaker overall performance.
The duplicate content problem extends beyond simple ranking confusion. Google’s algorithms are designed to identify and penalize sites that appear to be deliberately creating duplicate content for manipulation purposes. While shadow pages are usually unintentional, Google’s systems cannot always distinguish between accidental duplicates and intentional spam. This means your site risks receiving manual or algorithmic penalties that could significantly reduce your visibility across all search results, not just for the duplicated pages.
Backlinks are one of the most important ranking factors in Google’s algorithm, and they represent votes of confidence from other websites. When shadow pages accumulate backlinks—whether through internal linking or external references—that link equity gets distributed across multiple pages instead of being concentrated on your primary content. This dilution weakens the authority of your main pages and reduces their ability to rank for competitive keywords.
Internal linking becomes particularly problematic with shadow pages. If your site architecture creates multiple URLs for the same content, and some of these URLs receive internal links while others don’t, you’re essentially splitting your link equity. A page that should have received ten internal links might only receive five, while the shadow page version receives the other five. This fragmentation prevents any single page from accumulating enough authority to rank effectively for high-value keywords.
Set up advanced tracking in minutes. No credit card required.
Understanding how shadow pages form is essential for preventing them. Dynamic URL parameters represent one of the most common culprits, where session IDs, tracking codes, or user preferences create unique URLs for identical content. E-commerce sites frequently struggle with this issue when product filters, sorting options, or view preferences generate new URLs. Content management systems sometimes create shadow pages through pagination parameters, print-friendly versions, or mobile-specific URLs that aren’t properly consolidated with canonical tags.
Improper redirect implementation also generates shadow pages. When websites migrate content, change URL structures, or consolidate pages, old URLs should redirect to new ones using 301 redirects. If these redirects aren’t properly configured, search engines may index both the old and new URLs, creating duplicate content problems. Similarly, websites that fail to implement HTTPS redirects properly or don’t consolidate www and non-www versions create multiple shadow pages that compete for rankings.
Canonical tags tell search engines which version of a page should be considered the authoritative version when multiple URLs contain similar or identical content. By adding a rel=“canonical” tag to shadow pages, you consolidate ranking signals and prevent search engines from wasting crawl budget on duplicate versions. The canonical tag should point to the primary version of the page that you want to rank in search results.
Proper canonical implementation requires careful planning. For e-commerce sites with product filters, the canonical tag on filtered results should point to the base product page. For paginated content, each page should have a self-referential canonical tag, or you can use rel=“next” and rel=“prev” tags to indicate the relationship between pages. The key is ensuring that every shadow page clearly indicates which page should receive the ranking credit.
The noindex meta tag prevents search engines from indexing specific pages while still allowing them to be crawled and accessible to users. This approach works well for pages that serve internal purposes but shouldn’t appear in search results, such as thank-you pages, login pages, or internal search results. By applying noindex to shadow pages that don’t provide value to search users, you prevent them from consuming crawl budget and competing with your primary content.
Implementing noindex requires careful consideration to avoid accidentally blocking important pages. You should audit your site thoroughly to identify which pages genuinely don’t need to be indexed. Common candidates include duplicate content pages, thin content pages, and pages created for internal navigation or tracking purposes. Once identified, add the noindex tag to these pages and monitor Google Search Console to confirm they’re no longer appearing in search results.
The most effective long-term solution involves restructuring your site architecture to eliminate the conditions that create shadow pages. This means consolidating duplicate content into single authoritative pages, implementing proper URL structures that don’t generate unnecessary variations, and ensuring all important pages are properly linked from your site’s navigation and content.
For dynamic content, implement URL rewriting to create clean, static-looking URLs that don’t expose session IDs or tracking parameters. Use consistent URL structures across your site, and ensure that all variations of a page (mobile, desktop, print-friendly) use the same URL with responsive design or content negotiation rather than separate URLs. This approach not only eliminates shadow pages but also improves user experience and makes your site easier to crawl and index.
Be the first to know about new features and product updates.
| Tool | Purpose | Key Features |
|---|---|---|
| Google Search Console | Official indexation monitoring | Shows indexed vs. excluded pages, crawl errors, coverage issues |
| Screaming Frog | Technical SEO auditing | Crawls entire site, identifies duplicate content, finds redirect chains |
| Ahrefs | Comprehensive SEO analysis | Backlink analysis, crawl budget estimation, duplicate content detection |
| Semrush | Competitive analysis | Site audit features, technical SEO issues, page indexation status |
| Moz Pro | SEO toolset | Crawl diagnostics, duplicate content identification, rank tracking |
Regular site audits are essential for identifying and eliminating shadow pages before they damage your SEO performance. Google Search Console provides the most authoritative data about which pages Google has discovered and indexed. The Coverage report shows excluded pages and the reasons for exclusion, helping you identify shadow pages that search engines have decided not to index. The Excluded section often reveals shadow pages created by URL parameters, pagination, or redirect issues.
Screaming Frog offers a more comprehensive crawl of your entire site, simulating how search engines see your website. This tool can identify duplicate content, redirect chains, missing canonical tags, and other technical issues that create shadow pages. By regularly running Screaming Frog audits, you can catch shadow page problems before they significantly impact your SEO performance. The tool’s ability to identify pages with similar content helps you consolidate duplicates and improve your site structure.
Implementing best practices from the start prevents shadow pages from becoming a problem. Always use canonical tags on pages with similar content, especially on e-commerce sites with filtered results or paginated content. Ensure that your robots.txt file doesn’t accidentally block important pages while allowing shadow pages to be crawled. Configure your sitemap.xml to include only pages you want indexed, excluding shadow pages and thin content.
Establish clear URL structure guidelines for your development team. Avoid using session IDs, tracking parameters, or user preference indicators in URLs. Instead, implement these features through cookies or server-side sessions that don’t create new URLs. For dynamic content, use URL rewriting to create clean, consistent URLs that search engines can easily understand and index.
Implement proper 301 redirects whenever you change URL structures or consolidate pages. Monitor redirect chains to ensure they don’t exceed three hops, as excessive redirects waste crawl budget and can cause indexation issues. Test all redirects regularly to confirm they’re working correctly and pointing to the right destination pages.
Shadow pages represent a significant SEO challenge that can undermine your website’s search visibility and organic traffic potential. By wasting crawl budget, creating duplicate content problems, and diluting link equity, shadow pages prevent your most important content from receiving the attention it deserves from search engines. The good news is that shadow pages are largely preventable through proper site architecture, canonical tag implementation, and regular technical audits.
Taking action to eliminate shadow pages should be a priority in your 2025 SEO strategy. Start by auditing your site using Google Search Console and Screaming Frog to identify existing shadow pages. Implement canonical tags on duplicate content, use noindex directives on non-essential pages, and restructure your site architecture to prevent new shadow pages from forming. By addressing this technical SEO issue, you’ll improve your crawl efficiency, consolidate your ranking power, and ultimately achieve better search visibility and organic traffic for your business.
Shadow pages and technical SEO issues can significantly impact your affiliate marketing performance. PostAffiliatePro provides comprehensive tracking and analytics to help you identify and resolve SEO problems that affect your affiliate program's visibility and conversions. Monitor your affiliate pages, track performance metrics, and ensure all your content is properly indexed and optimized.
Discover why shadow domains are harmful black-hat SEO tactics. Learn about risks including search penalties, traffic diversion, brand confusion, and how to dete...
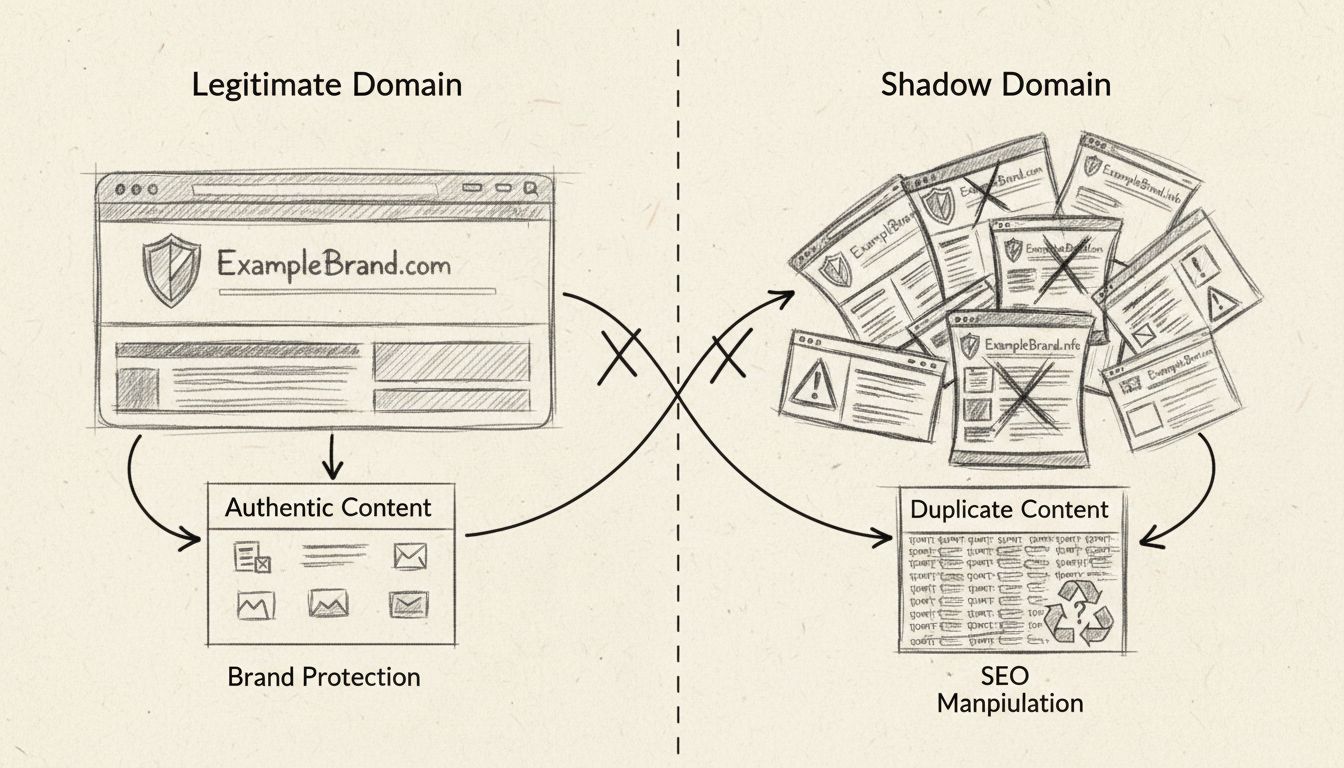
Shadow domains are unauthorized or malicious domains that imitate legitimate websites to divert traffic, manipulate search engine rankings, or carry out fraudul...
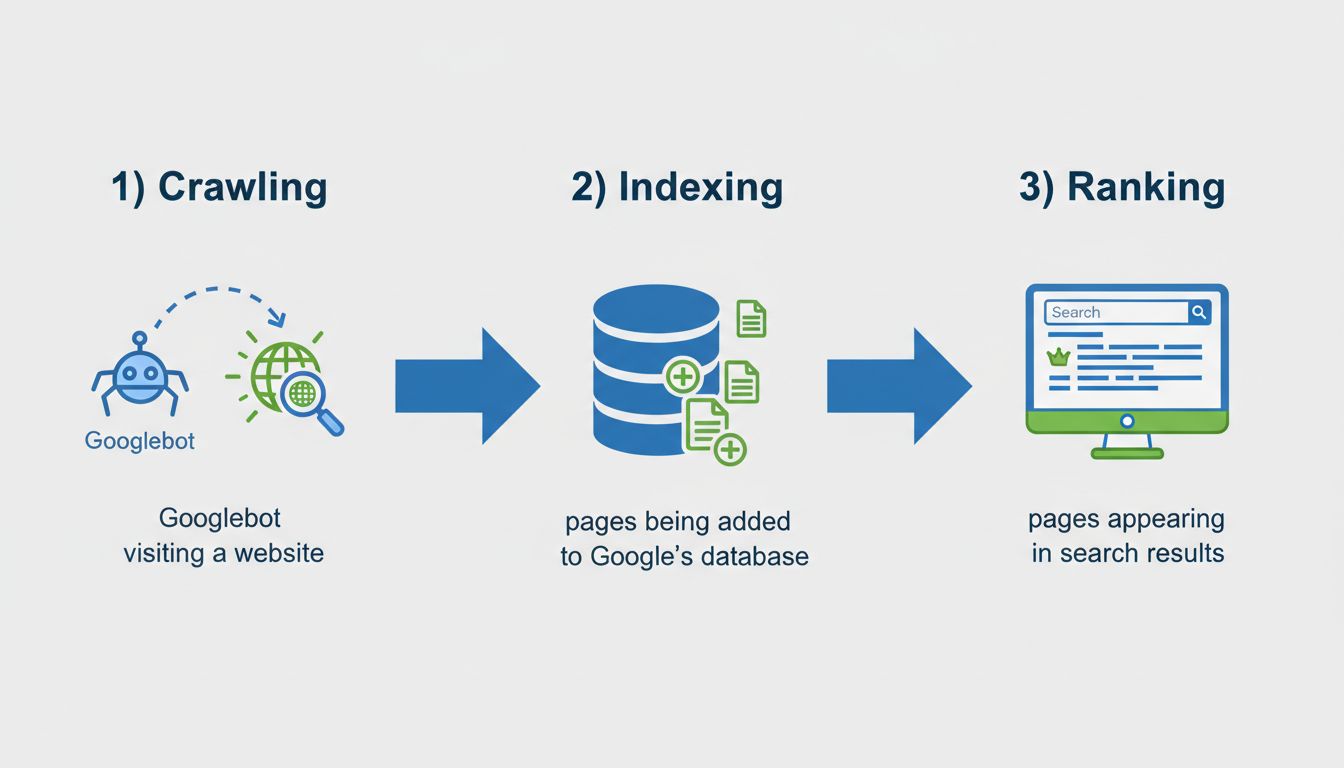
Learn what page indexing means, why pages aren't indexed by Google, and how to fix indexing issues. Discover technical solutions and best practices for 2025.
Join our community of happy clients and provide excellent customer support with Post Affiliate Pro.
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.