Why Are Web Spiders Called Computer Spiders? Understanding Web Crawlers
Learn why web spiders are called computer spiders and how they crawl the internet. Discover how search engine crawlers work and their importance for SEO and affiliate marketing.
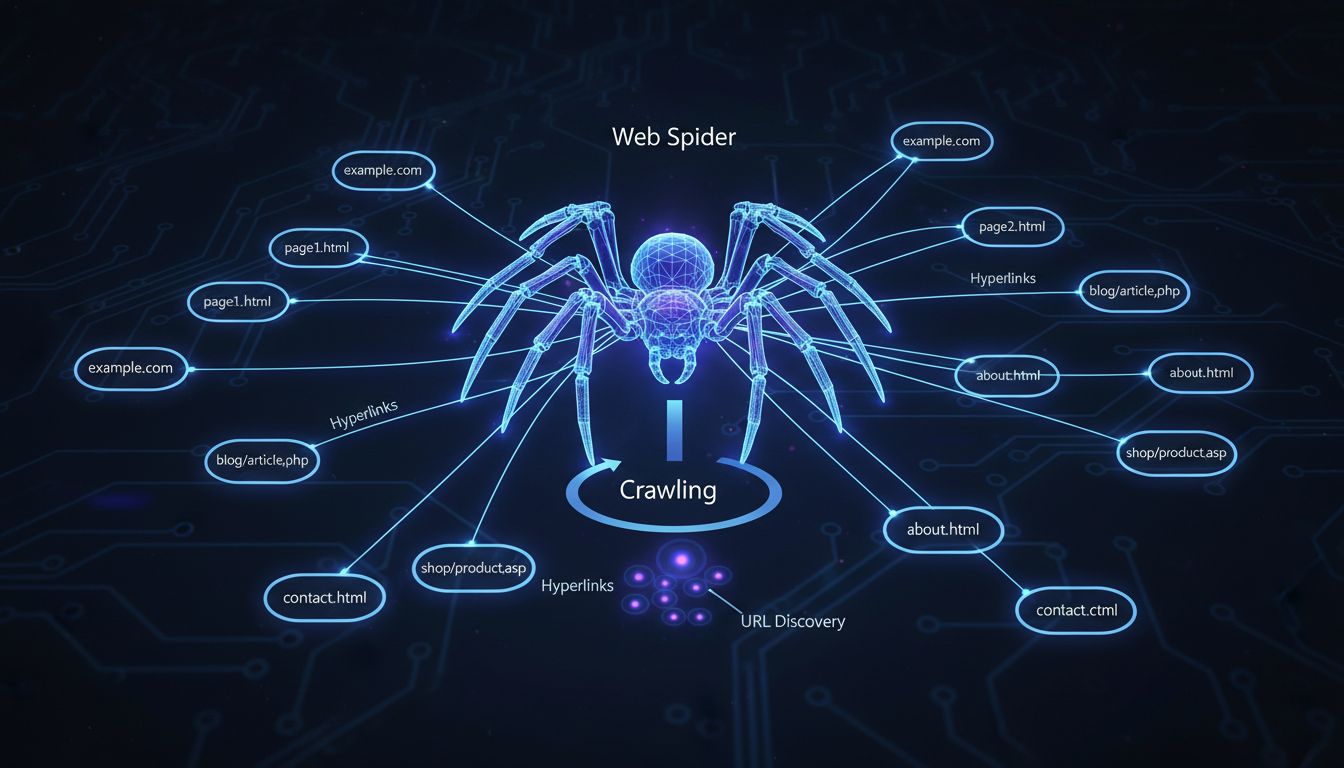
Why are they called computer spiders? They are called computer spiders because they "crawl" the web.
Web spiders are called computer spiders because they "crawl" across the internet by following hyperlinks from one page to another, much like a spider moves across its web. These automated programs systematically explore websites to discover and index content for search engines.
Understanding the Spider Metaphor
The term “computer spider” originates from a clever analogy that perfectly describes how these automated programs function on the internet. Just as a real spider moves across its web by following strands and connections, a web spider navigates the internet by following hyperlinks from one webpage to another. This metaphor has become so intuitive that it’s now the standard terminology used by web developers, SEO professionals, and digital marketers worldwide. The name captures the essence of the crawler’s behavior in a way that’s immediately understandable to both technical and non-technical audiences. When you understand this fundamental concept, you begin to appreciate how elegantly the internet’s infrastructure mirrors natural systems found in nature.
How Web Spiders Crawl the Internet
Web spiders operate through a systematic and methodical process that begins with a seed list of known URLs. The crawler starts by visiting these initial web pages and carefully examining their content and structure. As it processes each page, the spider identifies all hyperlinks present on that page and adds them to a queue of URLs to visit next. This process repeats continuously, allowing the spider to move deeper into the web with each iteration. The spider essentially creates a map of the internet by following these connections, much like an explorer charting new territory by following paths and trails. This systematic approach ensures that search engines can discover and catalog millions of new pages every single day.
Crawler Component
Function
Purpose
URL Queue
Stores list of pages to visit
Organizes crawling sequence
Parser
Reads page content and HTML
Extracts links and metadata
Indexer
Stores page information
Creates searchable database
Scheduler
Determines crawl frequency
Manages resource allocation
User-Agent
Identifies the crawler
Communicates with servers
The Technical Process Behind Web Crawling
Before a web spider begins its crawling operation, developers must establish clear, pre-defined instructions that guide the spider’s behavior. These instructions determine which pages to crawl, how frequently to revisit pages, and what information to extract from each page. The crawler then executes these instructions automatically, following the algorithm precisely as programmed. When the spider visits a website, it first checks the robots.txt file, which is a text file that specifies rules for crawler access. This protocol, known as the robot exclusion protocol, allows website owners to communicate their preferences about which areas of their site should be crawled and which should be avoided. The information gathered by the crawler depends entirely on the specific instructions provided to it, making the setup phase crucial for achieving desired results.
Different Types of Web Spiders
Web spiders come in various forms, each designed for specific purposes and applications. Search engine spiders like Googlebot are the most well-known type, used by major search engines to discover and index web pages for search results. Focused crawlers, on the other hand, limit their scope to specific topics or areas of the internet, creating detailed indexes of niche content. Web analysis spiders help webmasters monitor their own websites by tracking metrics such as site visits, broken links, and page performance. Price comparison spiders automatically gather pricing information from multiple vendors, allowing comparison websites to provide users with current market data. Email validation spiders verify email addresses and check for deliverability issues. Each type of spider serves a distinct purpose in the digital ecosystem, and understanding these differences helps website owners optimize their sites for the appropriate crawlers.
Why Search Engines Depend on Web Spiders
Search engines cannot function without web spiders because these automated programs are responsible for discovering new content and keeping search indexes current. When you perform a search query, the search engine doesn’t actually search the live internet in real-time. Instead, it searches through an index that was created by web spiders that previously visited and cataloged billions of web pages. Without spiders, search engines would have no way to know what content exists on the internet or how to organize it for retrieval. The spider’s ability to follow hyperlinks means that new pages can be discovered automatically without requiring manual submission. This automated discovery process is what makes the internet searchable and accessible to billions of users worldwide. The efficiency and speed of web spiders directly impact how quickly new content appears in search results.
The Importance of Web Spiders for SEO and Digital Marketing
For website owners and digital marketers, understanding web spiders is essential because these crawlers determine whether your content will appear in search results. If a search engine spider cannot crawl your website, your pages won’t be indexed and won’t show up in search results, regardless of how high-quality your content might be. This is why SEO professionals focus heavily on making websites “crawler-friendly” by ensuring proper site structure, fast loading times, and clear navigation. Affiliate marketers, in particular, benefit from understanding spider behavior because it directly impacts how their affiliate pages are discovered and ranked. PostAffiliatePro recognizes that successful affiliate programs depend on visibility, and our platform helps you optimize your affiliate network to ensure that search engine spiders can easily discover and index your affiliate content. By making your affiliate pages accessible to crawlers, you increase the likelihood that potential affiliates and customers will find your program through organic search.
Managing and Controlling Web Spider Activity
Website owners have several tools available to manage how web spiders interact with their sites. The robots.txt file is the primary mechanism for communicating crawler preferences, allowing you to specify which pages should be crawled and which should be avoided. The noindex meta tag provides additional control by preventing specific pages from being indexed even if they are crawled. For pages that should be crawled but not indexed, the nofollow attribute can be used on links to prevent spiders from following those particular connections. Website owners can also use the Google Search Console and other webmaster tools to monitor crawler activity and identify any issues that might prevent proper indexing. However, it’s important to note that while these tools help manage legitimate search engine spiders, malicious bots and scrapers may ignore these directives. This is why many websites implement additional security measures and bot management systems to protect against harmful crawler activity while still allowing beneficial spiders to access their content.
The Distinction Between Spiders and Scrapers
While web spiders and web scrapers both automatically collect data from websites, they serve very different purposes and operate under different ethical guidelines. Web spiders, particularly those used by search engines, follow the robots.txt protocol and respect website owner preferences about what content should be crawled. Scrapers, by contrast, often ignore these directives and copy entire pages of content to republish elsewhere, which can constitute copyright infringement and intellectual property theft. Spiders typically collect and organize metadata about pages, while scrapers copy the complete visible content. Search engine spiders are generally considered beneficial because they help websites gain visibility, whereas scrapers are typically viewed as malicious because they steal content and can harm website performance. Understanding this distinction is important for website owners who need to distinguish between legitimate crawler traffic and harmful bot activity. PostAffiliatePro helps affiliate managers monitor and manage traffic to their affiliate pages, ensuring that legitimate spiders can access your content while protecting against malicious scraping activity.
Maximize Your Affiliate Network Visibility
Just like web spiders discover and index your content, PostAffiliatePro helps you discover and manage your entire affiliate network. Track every crawler interaction and optimize your affiliate program's performance with our industry-leading platform.
Why Are Web Crawlers Called Spiders? Understanding Web Indexing Technology
Learn why web crawlers are called spiders, how they work, and their critical role in search engine indexing. Discover the technical mechanisms behind web crawli...